CVPR 2024 showcased groundbreaking AI and computer vision research, highlighting generative image dynamics, advanced 3D modeling, and innovative video editing techniques. OpenCV featured prominently, presenting OpenCV5 and collaborating with leading
YOLOv10 introduces a dual-head architecture for NMS-free training and efficiency-accuracy driven model design. It combines one-to-one and one-to-many label assignments to improve performance without extra computation. YOLOv10 uses lightweight classification
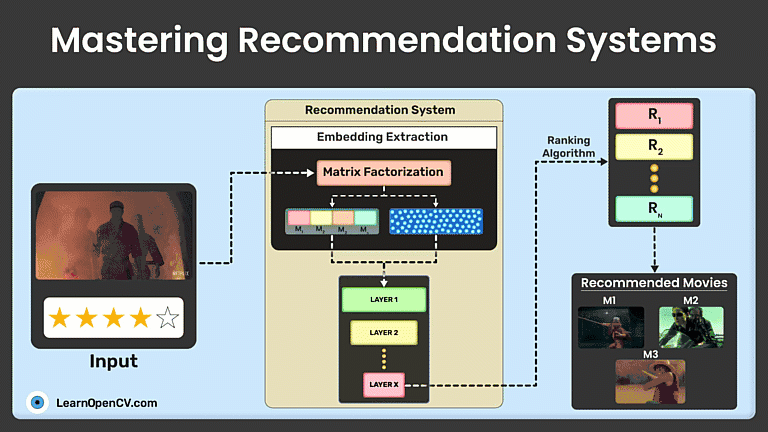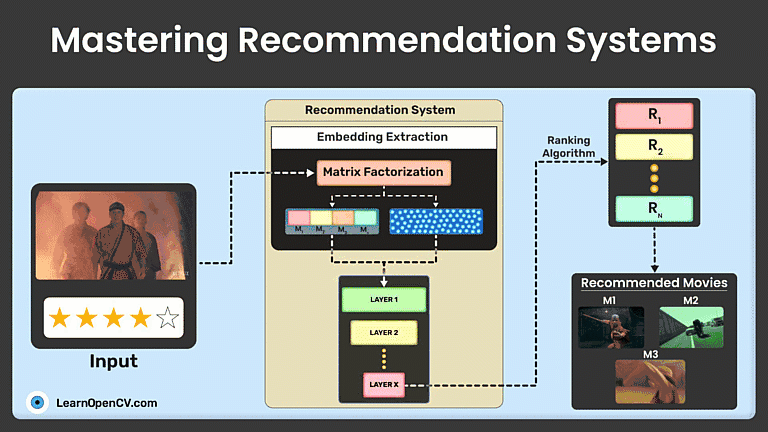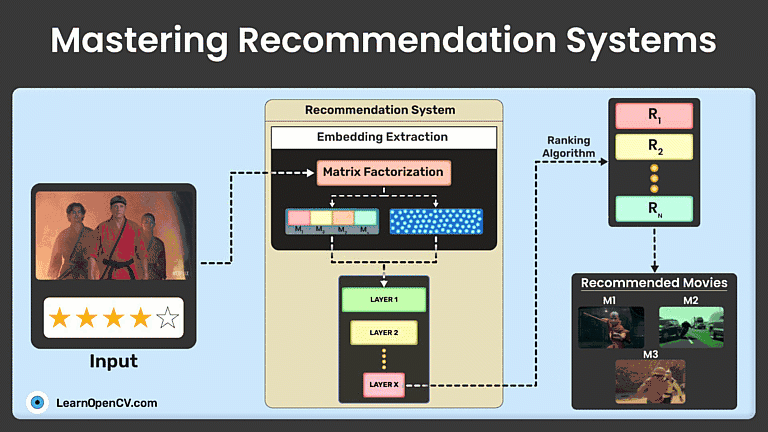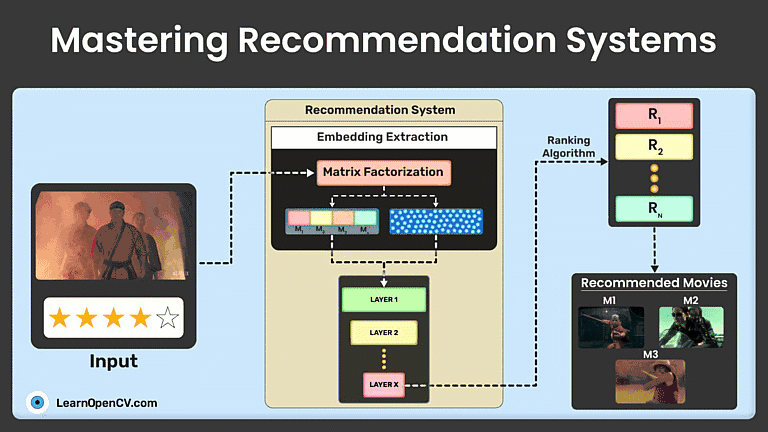
Recommendation systems (recommender systems) suggest content based on user preferences and behaviors. This guide explores their types, traditional ML techniques like matrix factorization, and advanced deep learning methods like neural
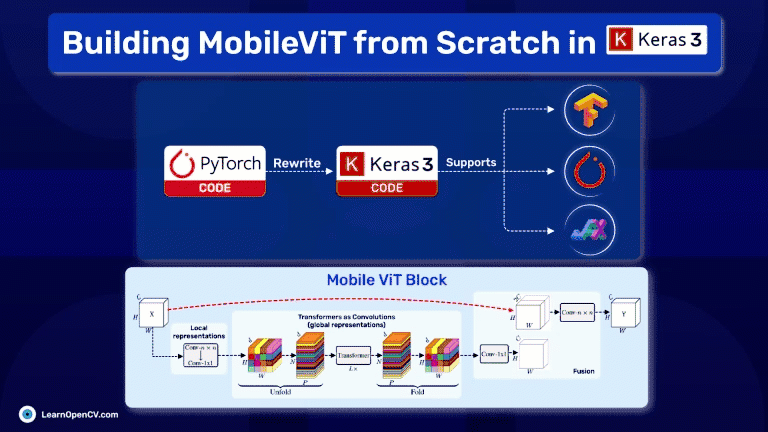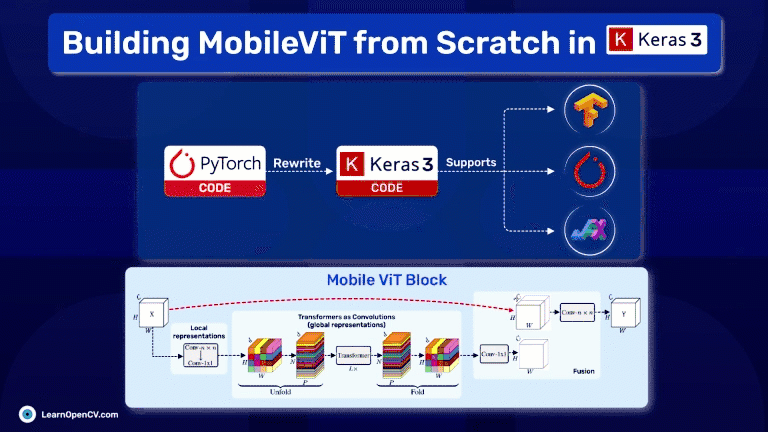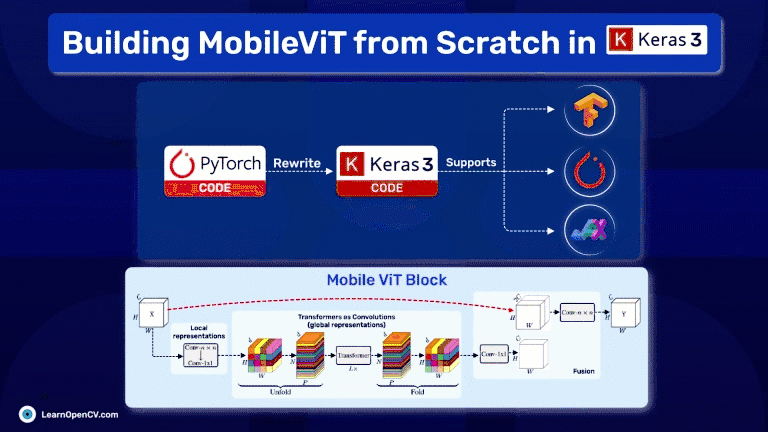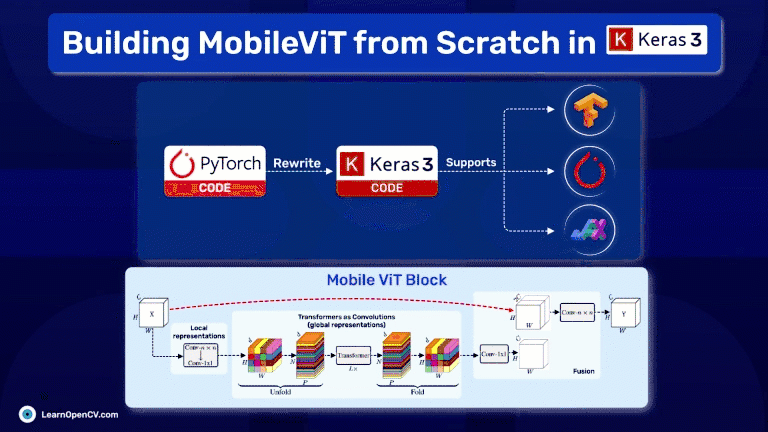
In the rapidly evolving field of deep learning, the challenge often lies not just in designing powerful models but also in making them accessible and efficient for practical use, especially
In the preceding article, YOLO Loss Functions Part 1, we focused exclusively on SIoU and Focal Loss as the primary loss functions used in the YOLO series of models. In
With millions of trainable parameters, neural networks have long been considered black boxes. They can produce stunning results, and we often accept the output with very little understanding as to