Discover VideoRAG, a framework that fuses graph-based reasoning and multi-modal retrieval to enhance LLMs' ability to understand multi-hour videos efficiently.
The ultimate goal for many in artificial intelligence is to build agents that can perceive, reason, and act in our complex physical world. Meta AI has made a significant stride
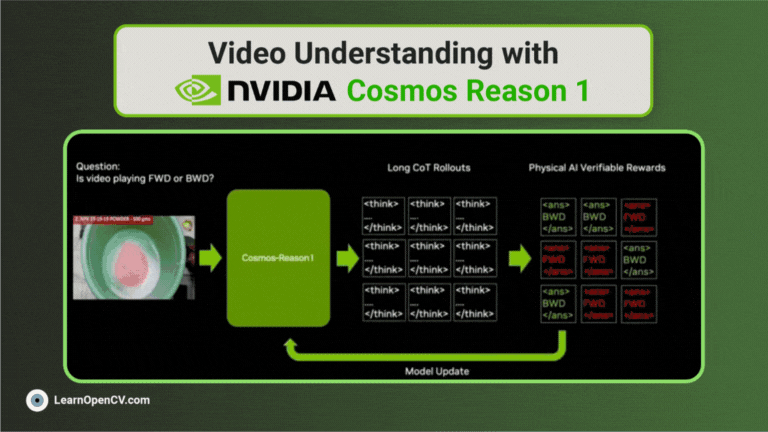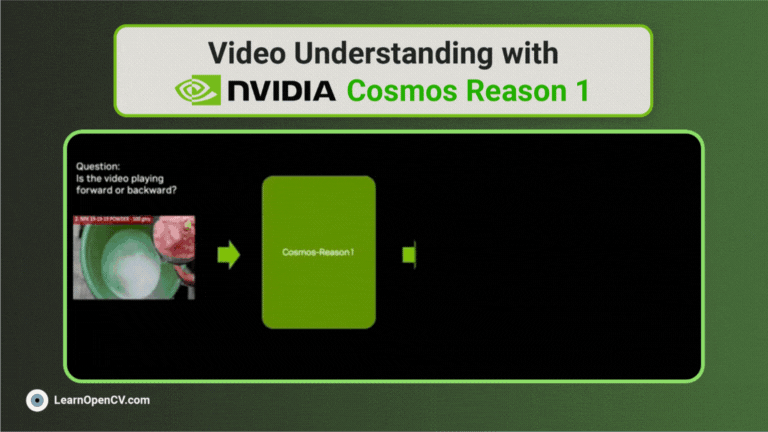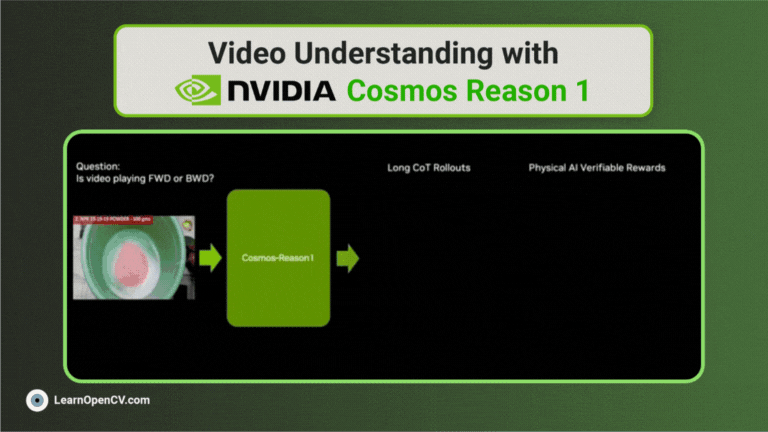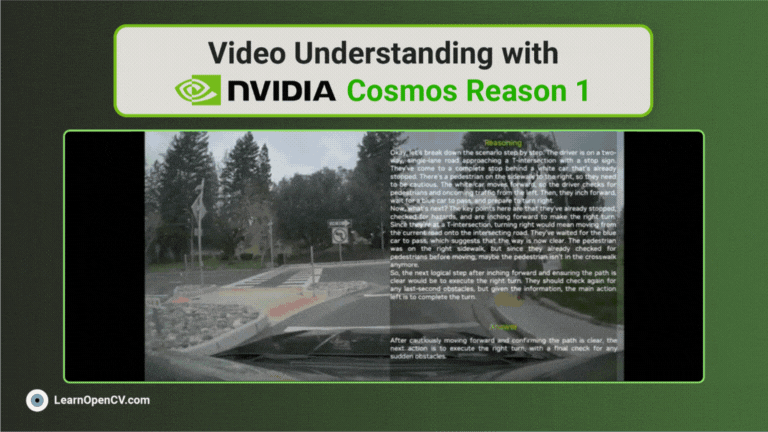
NVIDIA’s Cosmos Reason1 is a family of Vision Language Models trained to understand the physical world and make decisions for embodied reasoning. What makes Cosmos Reason1, as a promising contender