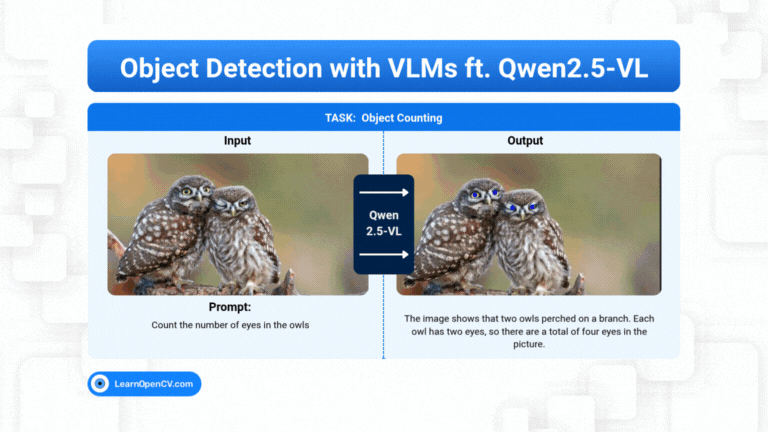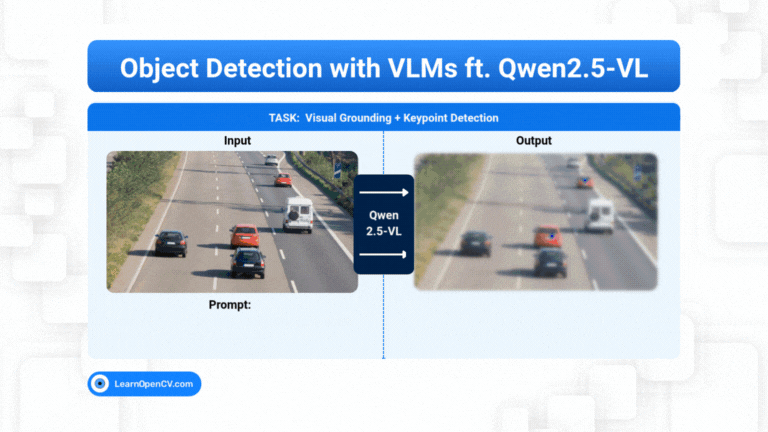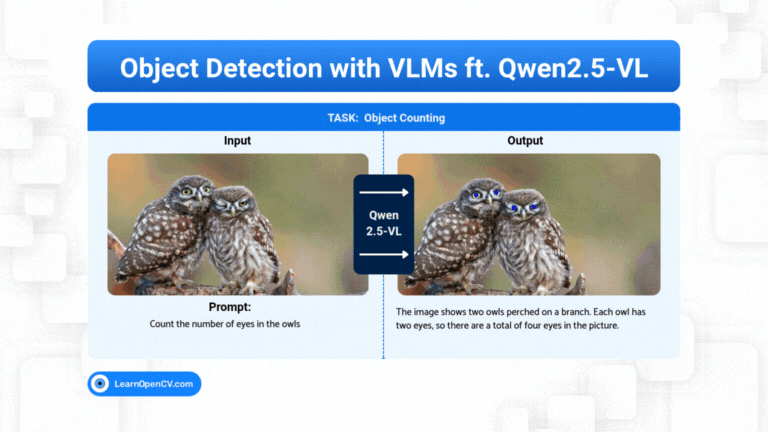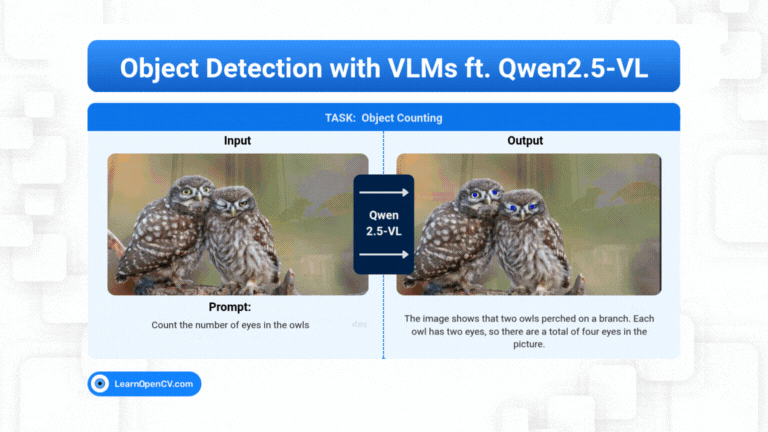
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
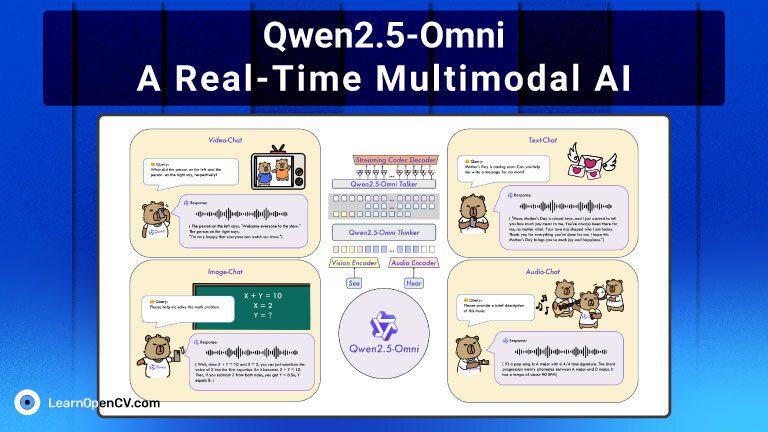
Qwen2.5-Omni is a groundbreaking end-to-end multimodal foundation model developed by Alibaba Qwen Group. In a unified and streaming manner, it’s designed to perceive and generate across multiple modalities – including