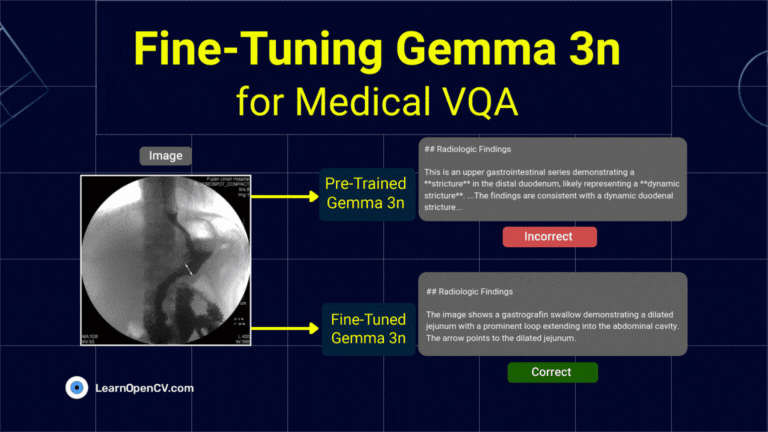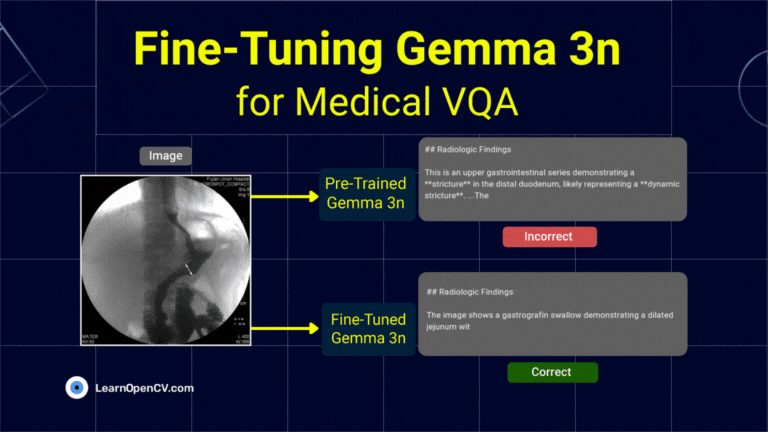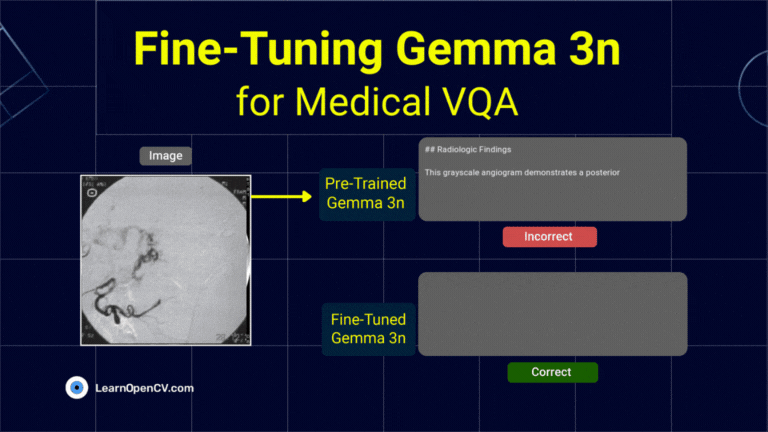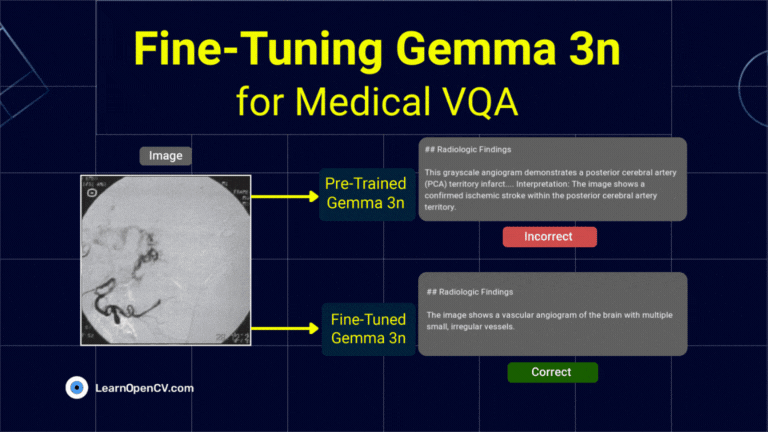
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
To develop AI systems that are genuinely capable in real-world settings, we need models that can process and integrate both visual and textual information with high precision. This is the
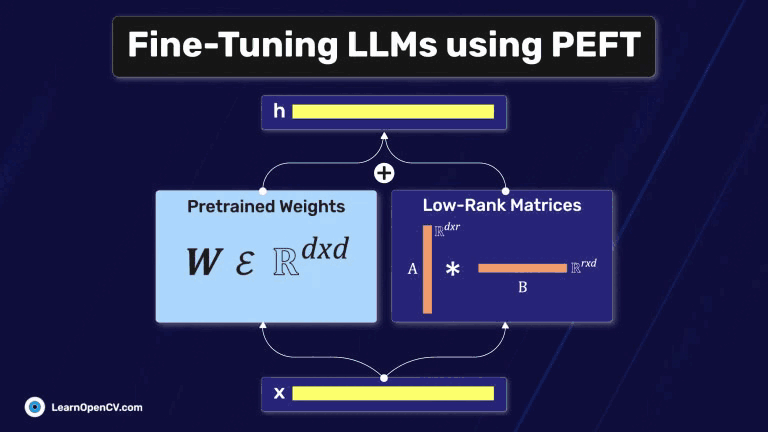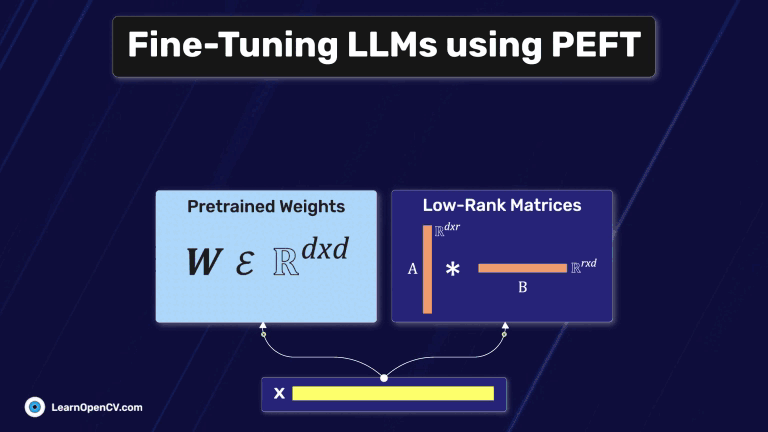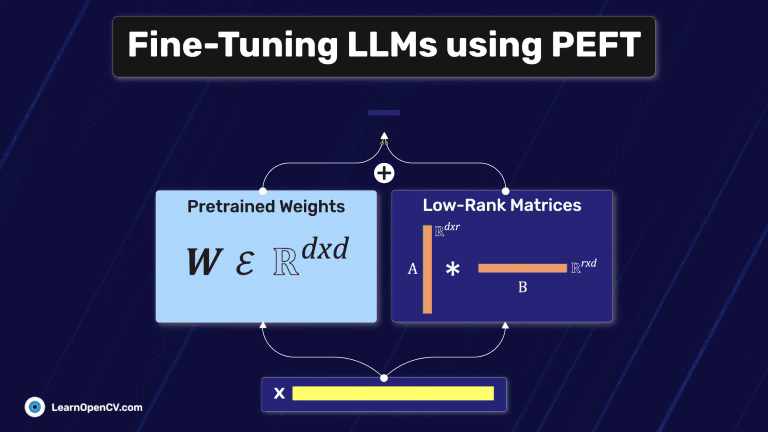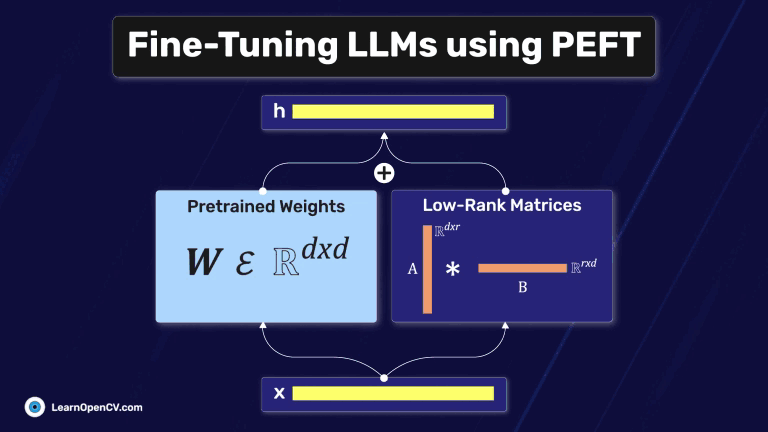
Fine-Tuning Gemma 3 allows us to adapt this advanced model to specific tasks, optimizing its performance for domain-specific applications. By leveraging QLoRA (Quantized Low-Rank Adaptation) and Transformers, we can efficiently
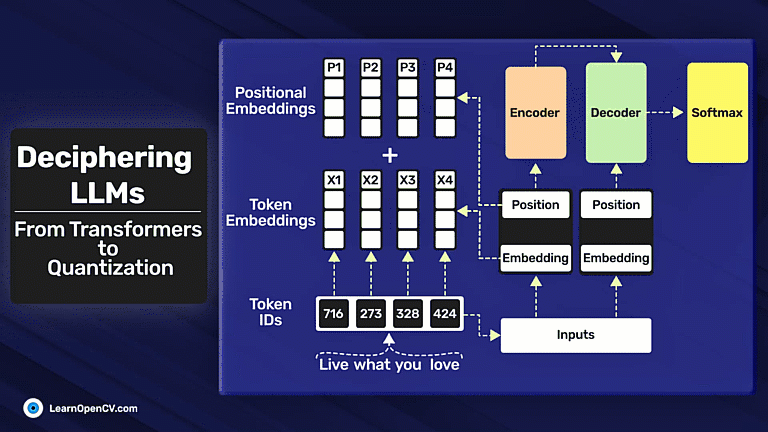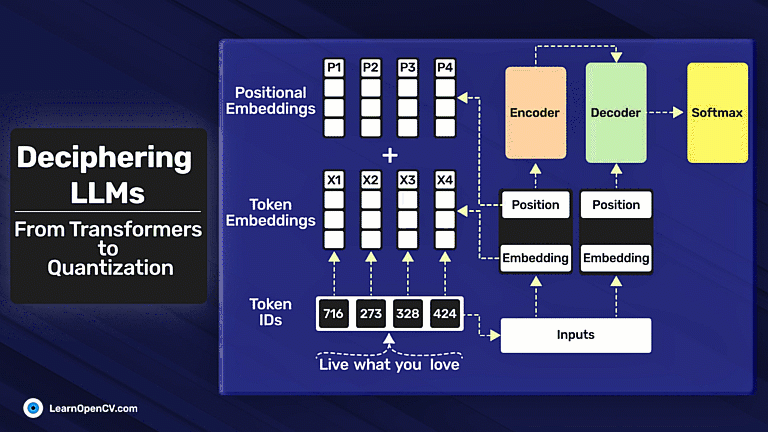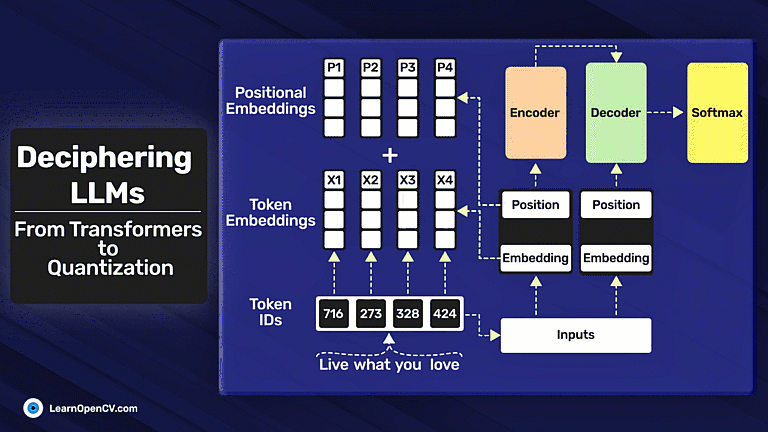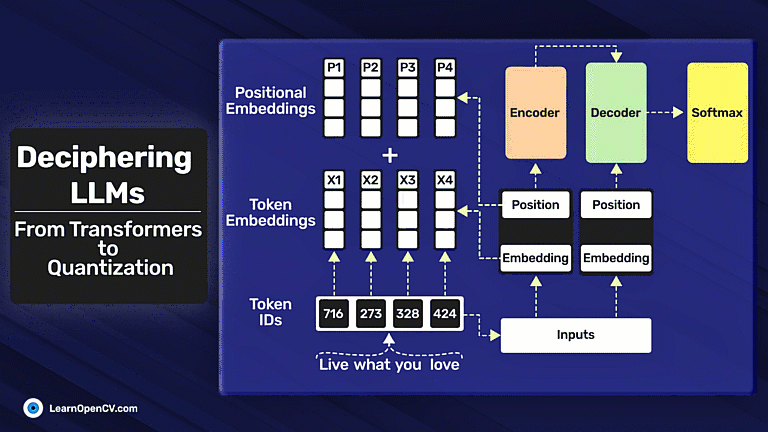
In this article, we explore different fine-tuning techniques for LLMs and fine-tune the FLAN T5 LLM using PEFT with the Hugging Face Transformers library.