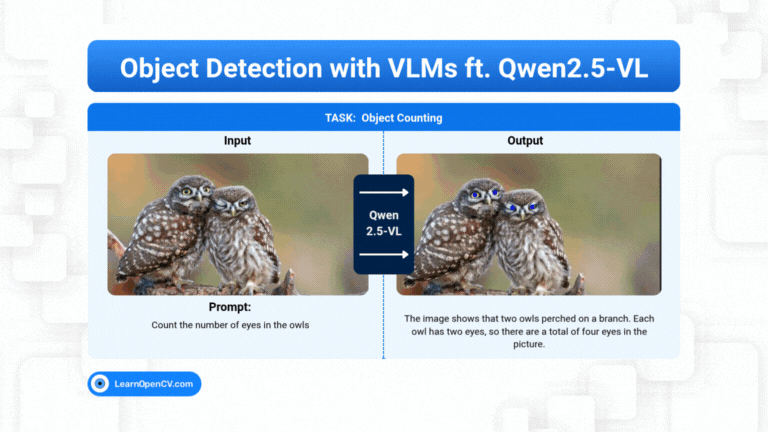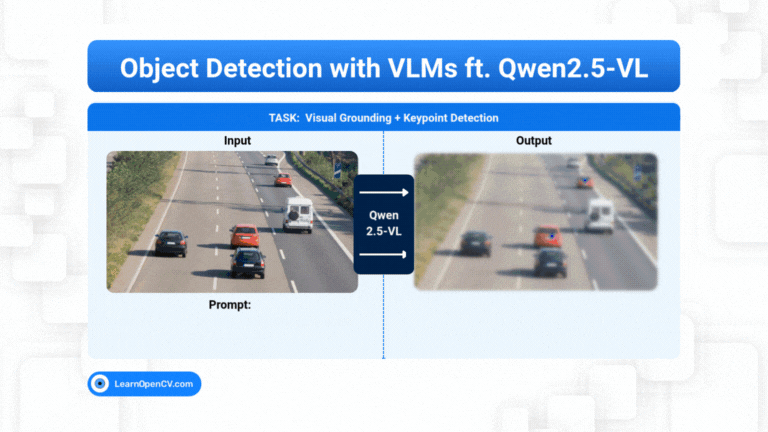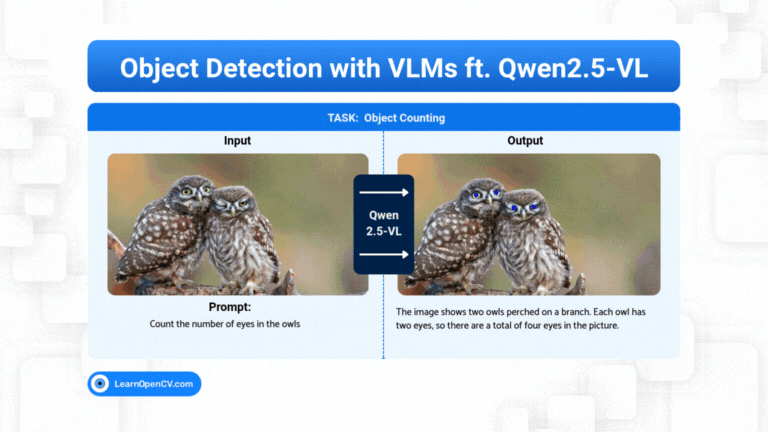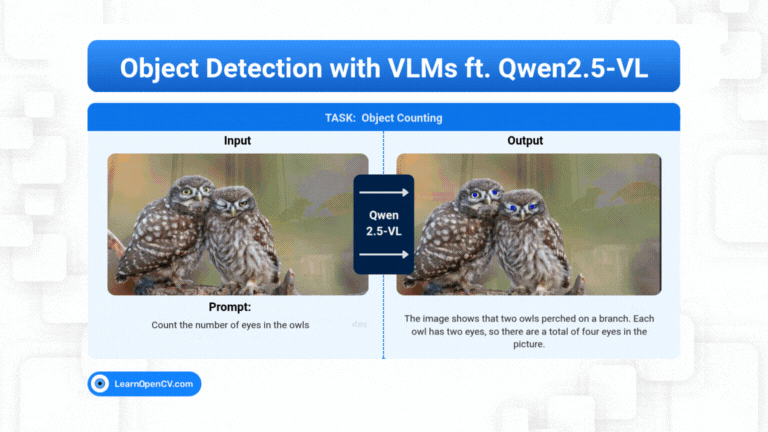
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
SimLingo is a remarkable model that combines autonomous driving, language understanding, and instruction-aware control—all in one unified, camera-only framework. It not only delivered top rankings on CARLA Leaderboard 2.0 and
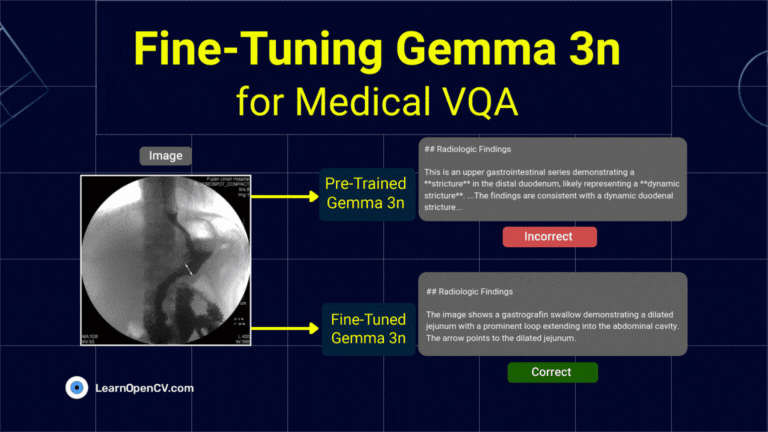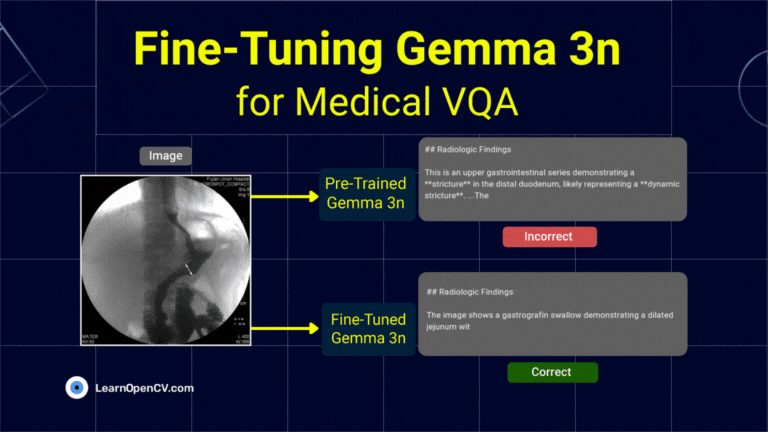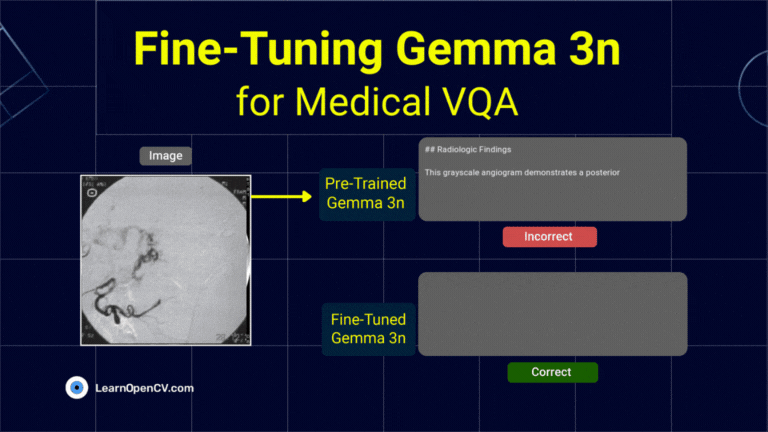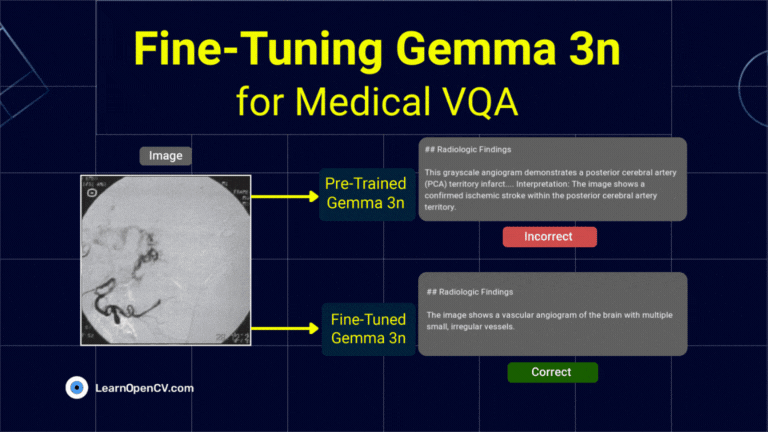
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
SigLIP-2 represents a significant step forward in the development of multilingual vision-language encoders, bringing enhanced semantic understanding, localization, and dense feature extraction capabilities. Built on the foundations of SigLIP, this
To develop AI systems that are genuinely capable in real-world settings, we need models that can process and integrate both visual and textual information with high precision. This is the
The landscape of Artificial Intelligence is rapidly evolving towards models that can seamlessly understand and generate information across multiple modalities, like text and images. Salesforce AI Research has introduced BLIP3-o,
GPT-4o image generation is a game-changer! With native support in ChatGPT, you can now create stunning visuals from text prompts, refine them, and explore styles like Studio Ghibli or photorealism.