What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
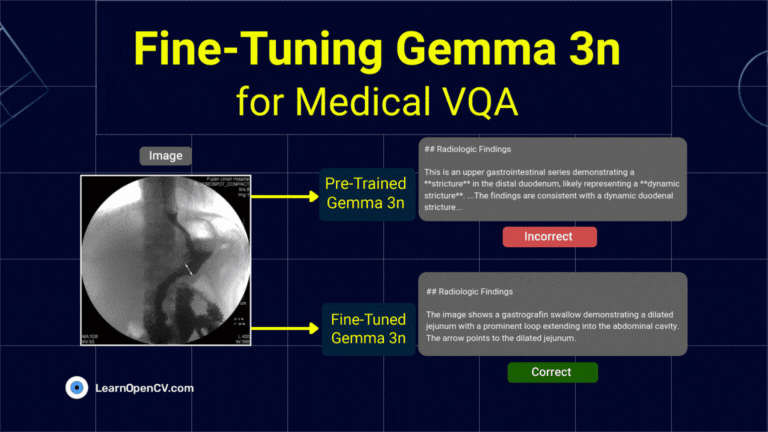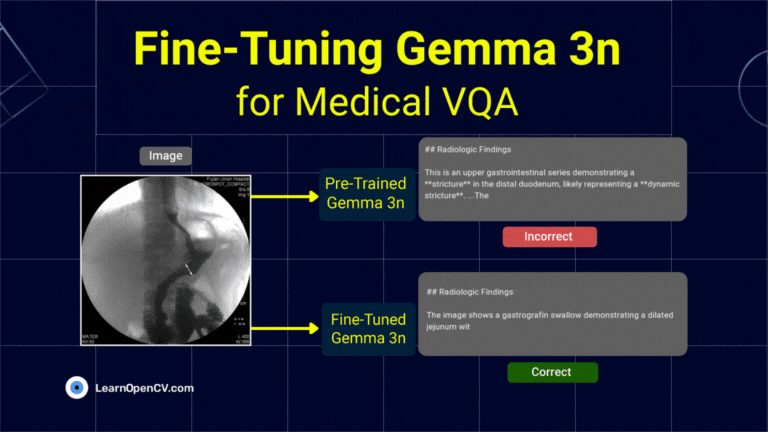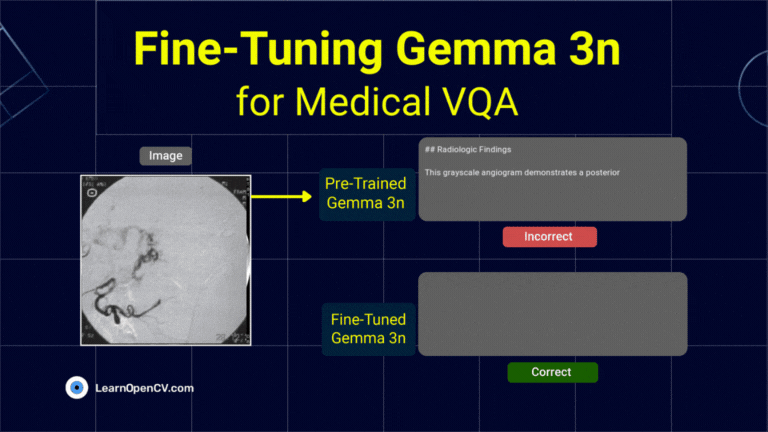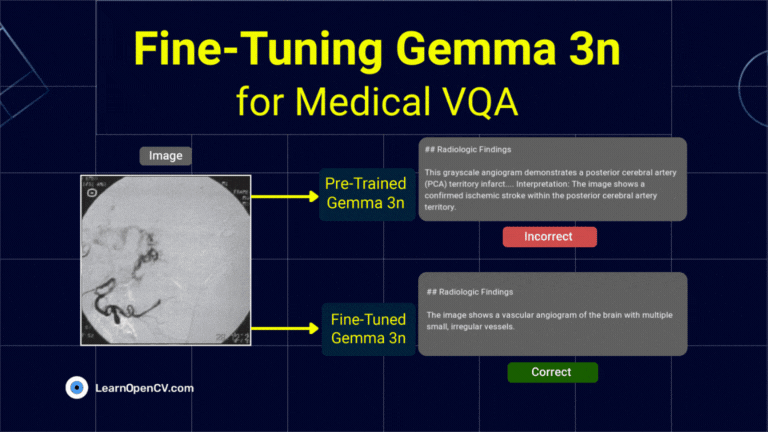
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
To develop AI systems that are genuinely capable in real-world settings, we need models that can process and integrate both visual and textual information with high precision. This is the
Imagine you’re a robotics enthusiast, a student, or even a seasoned developer, and you’ve been captivated by the idea of robots that can see, understand our language, and then act on that