

Imagine you’re a robotics enthusiast, a student, or even a seasoned developer, and you’ve been captivated by the idea of robots that can see, understand our language, and then act on that understanding. Maybe you’ve dreamed of building a robot arm that can help sort objects, follow your spoken instructions to tidy up a desk, or even assist with complex assembly tasks. For a long time, bringing such intelligent robots to life felt like something only accessible to large research labs with massive budgets and supercomputers. But hey, that long wait is pretty much over, because SmolVLA has arrived, and it’s here to solve exactly that!
Before the dawn of advanced AI models, teaching robots complex tasks was a painstaking ordeal of hardcoded programming, defining every scenario and movement. This made robots brittle and limited, unable to truly understand novel instructions or adapt to new situations based on visual input—that was pure science fiction. Then, Vision-Language Models (VLMs) and eventually Vision-Language-Action (VLA) models started to bridge this gap, learning from vast data to generally understand objects, scenes, and commands, translating “pick up the apple” into action by actually seeing and understanding.
However, these pioneering VLAs were often colossal, demanding massive computational resources and keeping them confined to well-funded research labs. But what if that barrier was significantly lowered again? What if you could experiment with, train, and deploy a powerful VLA model embodying this new robotic intelligence right on your consumer-grade GPU or decent laptop? This is exactly where SmolVLA steps into the limelight. It’s a compact yet surprisingly capable model designed to take the power of VLA robotics and make it genuinely accessible to everyone, built for efficiency, affordability, and openness, bringing advanced AI-driven robotics out of exclusive labs and into your hands.
SmolVLA, feels like a BERT moment for robotics
– Robotics Community
TL;DR – we will explore:
- What exactly SmolVLA is and its core mission.
- The clever architectural designs that make SmolVLA both “smol” (small) and powerful.
- How SmolVLA is trained using community-driven datasets.
- The magic of asynchronous inference that makes robots more responsive.
- A peek into SmolVLA’s performance and how you can get started with it.
This is the eighth article in our series of blogs on Robotics. If you are someone getting started with Robotics, our series of articles can be a good starting point:
- Introduction to Robotics: A Beginners Guide
- Introduction to ROS 2 (Robot Operating System 2)
- ROS 2 and Carla Setup Guide for Ubuntu 22.04
- Building Autonomous Vehicle in Carla: Path Following with PID Control & ROS 2
- Understanding Visual SLAM for Robotics Perception
- Introduction to LiDAR SLAM: LOAM and LeGO-LOAM : ROS 2 Implementation
- Vision Language Action Models (VLA) Overview: LeRobot Policies Demo
PS: In the last article in this robotics series, we provided a comprehensive overview of VLA. Do check it out if you missed it.
- Introduction to SmolVLA
- SmolVLA Architectural Key Innovations: Optimizing for Performance and Efficiency
- Asynchronous Inference
- The Fuel: Training on Community-Driven Datasets
- SmolVLA : LeRobot Training and Inference Pipeline
- Quick Recap
- Conclusion
- References
Introduction to SmolVLA

At its core, SmolVLA represents a significant step towards democratizing advanced robotics. It is a Vision-Language-Action model engineered for efficiency, enabling complex robotic tasks to be performed using systems with modest computational resources. The “Smol” designation refers to its compact architecture, approximately 450 million parameters, a figure notably smaller than many contemporary VLA models, which can scale into the billions of parameters. This reduced scale is pivotal, as it allows SmolVLA to be trained and deployed on consumer-grade GPUs, thereby lowering the barrier to entry for researchers, developers, and educational institutions. The overarching goal is to foster broader innovation in intelligent robotics by providing a capable yet accessible VLA framework.
SmolVLA Architectural Key Innovations: Optimizing for Performance and Efficiency
SmolVLA’s efficacy is not merely a consequence of its reduced size, but rather stems from intelligent architectural choices that optimize for both performance and computational thrift. The model integrates a pre-trained Vision-Language Model (VLM) for perception and linguistic comprehension with a specialized “action expert” module for translating cognitive understanding into physical actions.

- Leveraging an Efficient Vision-Language Backbone:
SmolVLA utilizes SmolVLM-2 as its perceptual and linguistic foundation. SmolVLM-2 is itself designed for efficient processing of multi-image and video inputs. Its key components include:- SigLIP: Employed for robust visual feature encoding.
- SmolLM2: A compact language model that processes textual instructions in conjunction with the encoded visual features.
This pre-trained backbone endows SmolVLA with a substantial degree of world knowledge and contextual understanding, forming a strong starting point for robotics-specific learning.
- Optimized Visual Processing:
To manage the high data throughput from visual sensors without incurring prohibitive computational costs, SmolVLA employs specific strategies:- Global Image Processing: Instead of relying on image tiling (processing multiple overlapping image crops), SmolVLA primarily processes the global image (resized to 512×512 pixels). This holistic approach is often sufficient for manipulation tasks and significantly reduces processing overhead.
- Visual Token Reduction: Techniques such as PixelShuffle are used to limit the number of visual tokens representing each image frame to approximately 64. This balances the need for visual detail with the imperative for rapid processing.
- Accelerated Inference via Layer Skipping:
A notable optimization within SmolVLA is the clever idea of layer skipping in the VLM’s language model component. Rather than extracting features from the last layer of the language model, SmolVLA’s action expert is conditioned on features from an intermediate layer, specifically around half the total layers (N = L/2). This architectural choice substantially reduces the computational path length for the action generation pathway during inference, yielding considerable speed improvements with a well-managed trade-off in performance. - The Flow Matching Action Expert for Smooth Kinematics:
The translation of processed perceptual data and instructions into robot actions is managed by the action expert (denoted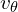 ).
). - Linear Projectors as Inter-Module Adapters:
Linear projection layers are strategically employed throughout the SmolVLA architecture. These layers function as dimensional and semantic adapters, ensuring compatibility between the outputs and inputs of different modules. For instance, they transform robot sensorimotor states into tokenized representations compatible with the VLM, and adapt VLM output features to the input requirements of the action expert.

Through this synergistic combination of architectural innovations, SmolVLA achieves a compelling balance between the rich representational capacity derived from its VLM backbone and the operational efficiency required for practical robotic applications.


Asynchronous Inference
Typically the sequence of action tokens generated by VLAs follows a synchronous approach, where the robot executes each action chunk, completes it and waits for next chunk to be predicted for subsequent movements.
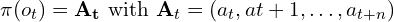
However, this approach introduces latency between actions ( 2 –> 3 ) which is ineffective. To mitigate this delay, the authors have integrated an async stack into the smolvla policy.
The asynchronous control loop executes the current action 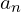 , but even before
, but even before 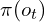 is completed, the robot client sends the latest state
is completed, the robot client sends the latest state 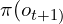 to Policy Server to predict next action. This intuitive design enables a decoupled thread (separate control loop) for parallel inferencing without blocking each other thereby reducing idle times. This also helps in generating smooth flows and avoids jittery movements.
to Policy Server to predict next action. This intuitive design enables a decoupled thread (separate control loop) for parallel inferencing without blocking each other thereby reducing idle times. This also helps in generating smooth flows and avoids jittery movements.

The following is the pseudo code provided for Asynchronous Inference Control Loop,

The Fuel: Training on Community-Driven Datasets

A model’s capabilities are intrinsically linked to the data it learns from. SmolVLA distinguishes itself by its foundational reliance on open, LeRobot community-driven datasets. This strategic choice moves away from dependence on large-scale, proprietary datasets, aligning instead with a philosophy of transparency and accessibility.
This data-sourcing strategy offers distinct advantages:
- Fostering Open Science and Reproducibility: Utilizing public datasets allows for greater transparency in model development and facilitates easier replication of results by the broader research community.
- Harnessing Diverse Data: The aggregate of community datasets, while individually perhaps less extensive than proprietary counterparts, offers significant diversity in terms of tasks, environmental conditions, camera perspectives, and even subtle variations in robot kinematics. For its pretraining, SmolVLA leveraged a curated set of 481 datasets, primarily for the SO-100 robotic arm, encompassing approximately 23,000 episodes (10.6 million frames).
- Exposure to Real-World Variability: Community datasets often capture the nuances and imperfections of real-world scenarios, which can contribute to the development of more robust and adaptable robot policies.
Despite these benefits, leveraging community-sourced data presents unique challenges that require systematic solutions:
- Addressing Data Heterogeneity:
- Task Annotation Normalization: A common issue is the inconsistency or vagueness in natural language descriptions accompanying the datasets. To mitigate this, the SmolVLA development team employed a supplementary VLM (Qwen2.5-VL-3B-Instruct) to auto-generate standardized, concise, action-oriented task descriptions from raw dataset inputs.
- Camera Viewpoint Standardization: Inconsistent camera naming conventions across datasets can introduce ambiguity. A manual mapping process was implemented to standardize camera views (e.g., OBS_IMAGE_1 for top-down, OBS_IMAGE_2 for wrist-mounted), ensuring consistent input for the model.
The empirical results underscore the value of this approach. Pretraining SmolVLA on this corpus of community datasets led to a substantial improvement in real-world performance on the SO-100 robot benchmark, elevating success rates from 51.7% (task-specific training only) to 78.3%. This highlights the efficacy of knowledge transfer from diverse, open datasets in building more generalized and capable robotic agents.

SmolVLA : LeRobot Training and Inference Pipeline
Create a new environment and setup lerobot locally. For this training experiment we are using a i7 13th gen RTX 3080Ti (12GB VRAM) GPU. There was a steady GPU consumption of ~11.53 GB with a batch size of 44 (yes, it’s not the standard 32 or 64). Consider using a batch size of 16 if you have 6GB laptop GPUs.
conda create -y -n lerobot python=3.10
conda activate lerobot
Setting up LeRobot locally
As next steps, we will clone the lerobot repository and install the necessary dependencies required for out smolvla policy training.
git clone https://github.com/huggingface/lerobot.git
cd lerobot
pip install -e ".[smolvla]"
Make sure to login with your Hugging Face credential and pass your hf_token to avoid 401 unauthorizated for url error.
pip install -U "huggingface_hub[cli]"
huggingface-cli login
Dataset creation
The episodes for training are provided by the LeRobot HF team from a communtiy dataset collection hosted as lerobot/svla_so100_stacking as the test bed for the training was done either using so-100 or so-101 robot arm. A total of 174 episodes of filtered robot data are downloaded when you run the Smolvla policy for the first time. The following are the logs that one will observe will during dataset preparation.
INFO 2025-06-05 18:04:12 ts/train.py:111 {'batch_size': 16,
'dataset': {'episodes': None,
'image_transforms': {'enable': False,
'max_num_transforms': 3,
'random_order': False,
'tfs': {'brightness': {'kwargs': {'brightness': [0.8,
1.2]},
'type': 'ColorJitter',
'weight': 1.0},
'contrast': {'kwargs': {'contrast': [0.8,
1.2]},
'type': 'ColorJitter',
'weight': 1.0},
'hue': {'kwargs': {'hue': [-0.05,
0.05]},
'type': 'ColorJitter',
'weight': 1.0},
'saturation': {'kwargs': {'saturation': [0.5,
1.5]},
'type': 'ColorJitter',
'weight': 1.0},
'sharpness': {'kwargs': {'sharpness': [0.5,
1.5]},
'type': 'SharpnessJitter',
'weight': 1.0}}},
'repo_id': 'lerobot/svla_so100_stacking',
'revision': None,
'root': None,
'use_imagenet_stats': True,
'video_backend': 'torchcodec'},
'env': None,
'eval': {'batch_size': 50, 'n_episodes': 50, 'use_async_envs': False},
'eval_freq': 20000,
'job_name': 'smolvla',
'log_freq': 200,
'num_workers': 4,
'optimizer': {'betas': [0.9, 0.95],
'eps': 1e-08,
'grad_clip_norm': 10.0,
'lr': 0.0001,
'type': 'adamw',
'weight_decay': 1e-10},
'output_dir': 'outputs/train/2025-06-05/18-04-12_smolvla',
'policy': {'adapt_to_pi_aloha': False,
'add_image_special_tokens': False,
'attention_mode': 'cross_attn',
'chunk_size': 50,
'device': 'cuda',
'empty_cameras': 0,
'expert_width_multiplier': 0.75,
'freeze_vision_encoder': True,
'input_features': {'observation.image': {'shape': [3, 256, 256],
'type': <FeatureType.VISUAL: 'VISUAL'>},
'observation.image2': {'shape': [3, 256, 256],
'type': <FeatureType.VISUAL: 'VISUAL'>},
'observation.image3': {'shape': [3, 256, 256],
'type': <FeatureType.VISUAL: 'VISUAL'>},
'observation.state': {'shape': [6],
'type': <FeatureType.STATE: 'STATE'>}},
'load_vlm_weights': True,
'max_action_dim': 32,
'max_period': 4.0,
'max_state_dim': 32,
'min_period': 0.004,
'n_action_steps': 1,
'n_obs_steps': 1,
'normalization_mapping': {'ACTION': <NormalizationMode.MEAN_STD: 'MEAN_STD'>,
'STATE': <NormalizationMode.MEAN_STD: 'MEAN_STD'>,
'VISUAL': <NormalizationMode.IDENTITY: 'IDENTITY'>},
'num_expert_layers': 0,
'num_steps': 10,
'num_vlm_layers': 16,
'optimizer_betas': [0.9, 0.95],
'optimizer_eps': 1e-08,
'optimizer_grad_clip_norm': 10.0,
'optimizer_lr': 0.0001,
'optimizer_weight_decay': 1e-10,
'output_features': {'action': {'shape': [6],
'type': <FeatureType.ACTION: 'ACTION'>}},
'pad_language_to': 'max_length',
'prefix_length': 0,
'resize_imgs_with_padding': [512, 512],
'scheduler_decay_lr': 2.5e-06,
'scheduler_decay_steps': 30000,
'scheduler_warmup_steps': 1000,
'self_attn_every_n_layers': 2,
'tokenizer_max_length': 48,
'train_expert_only': True,
'train_state_proj': True,
'type': 'smolvla',
'use_amp': False,
'use_cache': True,
'use_delta_joint_actions_aloha': False,
'vlm_model_name': 'HuggingFaceTB/SmolVLM2-500M-Video-Instruct'},
'resume': False,
'save_checkpoint': True,
'save_freq': 20000,
'scheduler': {'decay_lr': 2.5e-06,
'num_decay_steps': 30000,
'num_warmup_steps': 1000,
'peak_lr': 0.0001,
'type': 'cosine_decay_with_warmup'},
'seed': 1000,
'steps': 200000,
'use_policy_training_preset': True,
'wandb': {'disable_artifact': False,
'enable': False,
'entity': None,
'mode': None,
'notes': None,
'project': 'lerobot',
'run_id': None}}
INFO 2025-06-05 18:04:12 ts/train.py:117 Logs will be saved locally.
INFO 2025-06-05 18:04:12 ts/train.py:127 Creating dataset
Resolving data files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 56/56 [00:00<00:00, 389520.77it/s]
Visualize Dataset using Rerun
python lerobot/scripts/visualize_dataset.py \
--repo-id lerobot/svla_so100_stacking \
--episode-index 40

SmolVLA Training
We can either fine-tune the pre-trained smolvla_base checkpoint or train it from scratch. For our experiments we are leveraging proceeding with fine-tuning the pre-trained weights.
Hyperparameters for fine-tuning and training are
- Batch size = 64
- Steps = 200000 (200K)
python lerobot/scripts/train.py \
--policy.path=lerobot/smolvla_base \
--dataset.repo_id=lerobot/svla_so100_stacking \
--batch_size=64 \
--steps=200000
INFO 2025-06-05 17:58:48 ts/train.py:138 Creating policy
Loading HuggingFaceTB/SmolVLM2-500M-Video-Instruct weights ...
INFO 2025-06-05 17:58:54 modeling.py:991 We will use 90% of the memory on device 0 for storing the model, and 10% for the buffer to avoid OOM. You can set `max_memory` in to a higher value to use more memory (at your own risk).
Reducing the number of VLM layers to 16 ...
INFO 2025-06-05 17:59:04 ts/train.py:144 Creating optimizer and scheduler
INFO 2025-06-05 17:59:04 ts/train.py:156 Output dir: outputs/train/2025-06-05/17-58-47_smolvla
INFO 2025-06-05 17:59:04 ts/train.py:159 cfg.steps=200000 (200K)
INFO 2025-06-05 17:59:04 ts/train.py:160 dataset.num_frames=22956 (23K)
INFO 2025-06-05 17:59:04 ts/train.py:161 dataset.num_episodes=56
INFO 2025-06-05 17:59:04 ts/train.py:162 num_learnable_params=99880992 (100M)
INFO 2025-06-05 17:59:04 ts/train.py:163 num_total_params=450046212 (450M)
INFO 2025-06-05 17:59:04 ts/train.py:202 Start offline training on a fixed dataset
INFO 2025-06-05 18:02:06 ts/train.py:232 step:200 smpl:3K ep:8 epch:0.14 loss:1.198 grdn:4.102 lr:1.0e-05 updt_s:0.907 data_s:0.005
. . .
INFO 2025-06-07 11:36:25 ts/train.py:232 step:200K smpl:9M ep:21K epch:383.34 loss:0.004 grdn:0.106 lr:2.5e-06 updt_s:0.731 data_s:0.005
INFO 2025-06-07 11:36:25 ts/train.py:241 Checkpoint policy after step 200000
INFO 2025-06-07 11:36:26 ts/train.py:283 End of training
Once training is completed the checkpoints are saved. The training started with a loss of 1.198 and converged to 0.004 after 200K steps.
(lerobot) opencvuniv@opencvuniv:~/.../checkpoints/last$ tree
.
├── pretrained_model
│ ├── config.json
│ ├── model.safetensors
│ └── train_config.json
└── training_state
├── optimizer_param_groups.json
├── optimizer_state.safetensors
├── rng_state.safetensors
├── scheduler_state.json
└── training_step.json
To train the smolvla_base model from scratch, just specify the policy type
python lerobot/scripts/train.py \
--policy.type=smolvla \
--dataset.repo_id=lerobot/svla_so100_stacking \
--batch_size=64 \
--steps=200000
SmolVLA Inference
We can also load the pretrained model directly using the SmolVLAPolicy.
import torch
import time
from lerobot.common.policies.smolvla.modeling_smolvla import SmolVLAPolicy
from lerobot.common.policies.smolvla.configuration_smolvla import SmolVLAConfig
from transformers import AutoProcessor
# Load model (replace with your checkpoint if needed)
policy = SmolVLAPolicy.from_pretrained(
"/home/opencvuniv/lerobot/outputs/train/2025-06-05/18-49-20_smolvla/checkpoints/last/pretrained_model"
).to("cuda")
policy.eval()
# patch: The loaded policy is missing the language_tokenizer attribute.
policy.language_tokenizer = AutoProcessor.from_pretrained(policy.config.vlm_model_name).tokenizer
# Dummy batch config for a single observation
batch_size = 1
img_shape = (3, 512, 512) # (C, H, W)
# Infer state_dim from the loaded normalization stats
state_dim = policy.normalize_inputs.buffer_observation_state.mean.shape[-1]
dummy_batch = {
# a single image observation
"observation.images.top": torch.rand(batch_size, *img_shape, device="cuda"),
# a single state observation
"observation.state": torch.rand(batch_size, state_dim, device="cuda"),
"task": ["stack the blocks"] * batch_size,
}
# --- Prepare inputs for the model ---
# The policy expects normalized inputs and specific data preparation.
normalized_batch = policy.normalize_inputs(dummy_batch)
images, img_masks = policy.prepare_images(normalized_batch)
state = policy.prepare_state(normalized_batch)
lang_tokens, lang_masks = policy.prepare_language(normalized_batch)
# ---
# Warmup
for _ in range(3):
with torch.no_grad():
_ = policy.model.sample_actions(images, img_masks, lang_tokens, lang_masks, state)
# Benchmark
torch.cuda.reset_peak_memory_stats()
start = time.time()
for _ in range(100):
with torch.no_grad():
_ = policy.model.sample_actions(images, img_masks, lang_tokens, lang_masks, state)
end = time.time()
print(f"Avg inference time: {(end - start)/100:.6f} s")
print(f"Max GPU memory used: {torch.cuda.max_memory_allocated() / 1024**2:.2f} MB")
#Avg inference time: 0.086982 s
#Max GPU memory used: 908.43 MB
Limitations of SmolVLA (And Future Directions)
While SmolVLA represents a fantastic leap forward in making Vision-Language-Action models more accessible and efficient, like any pioneering technology, it has its current boundaries and areas ripe for future exploration. Understanding these limitations is key for both users and developers looking to build upon this work. The creators themselves highlight several points:
- Dataset Diversity and Cross-Embodiment Training:
- Current Scope: SmolVLA’s pretraining, while using diverse community datasets, primarily focused on data collected from a single robot type (the SO100 arm).
- The Challenge: True robotic intelligence often requires the ability to generalize across different robot shapes and capabilities (embodiments). For example, skills learned on a 6-DOF arm might not directly transfer to a mobile robot or a humanoid.
- Future Path: Incorporating training data from a wider variety of robot embodiments is a crucial next step. This would likely enhance SmolVLA’s ability to adapt to new robotic platforms with less fine-tuning, making it even more versatile.
- Dataset Size and Scalability for Pretraining:
- Current Scale: The pretraining dataset for SmolVLA, around 23,000 trajectories, is significantly smaller than those used for some larger VLA regimes (which can run into a million trajectories, like OpenVLA).
- The Impact: While SmolVLA performs impressively, larger and even more diverse pretraining datasets could substantially boost its performance further, particularly in its generalization across a wider array of tasks and environments.
- Future Path: Continuously expanding the scale and scope of pretraining data, especially high-quality community contributions, will be vital.
- Model Size and Hardware Efficiency – The “Smol” Frontier:
- Current Achievement: At under 0.5 billion parameters, SmolVLA is remarkably efficient for its capabilities, running on consumer-grade hardware.
- The Quest: The pursuit of efficiency is ongoing. Can we make these models even smaller or faster without sacrificing performance?
- Future Path: Exploring new architectural innovations, quantization techniques, and hardware-specific optimizations could push the boundaries of “smol” even further, making powerful robotics AI accessible on even more constrained devices.
- Choice of VLM Backbone:
- Current Backbone: SmolVLA uses SmolVLM-2, which is an off-the-shelf VLM mainly pretrained on tasks like document understanding and OCR.
- The Question: While effective, is a VLM trained primarily on text and static images the absolute optimal starting point for a robot that needs to understand dynamic 3D environments and physical interactions?
- Future Path: Future work could explore VLM backbones that are more specifically pretrained for robotics-relevant scenarios, perhaps with more emphasis on video understanding, 3D perception, or physical common sense. This could lead to better alignment with the unique demands of robotic environments.
- Multimodal and Robotics Data Joint Training:
- Current Approach: SmolVLA is pretrained on robotics datasets.
- The Potential: There’s a hypothesis that jointly training models on both broad multimodal datasets (general text, images, videos) and robotics-specific data could lead to VLAs with even stronger generalization and instruction-following capabilities.
- Future Path: Investigating strategies for such joint training could produce more robust and adaptable VLAs.
- Task Complexity and Longer Horizons:
- Current Performance: SmolVLA competes effectively on relatively simple, short-horizon tasks.
- The Challenge: Scaling these approaches to handle complex, multi-stage tasks that unfold over longer time periods (e.g., “clean the kitchen”) remains a significant hurdle in robotics.
- Future Path: Incorporating hierarchical policies (where a high-level planner breaks down big tasks into smaller ones for SmolVLA to execute) or more advanced multi-level planning mechanisms could be key to tackling this complexity.
- Learning Paradigms: Beyond Imitation Learning:
- Current Method: SmolVLA primarily relies on imitation learning (learning from demonstrations).
- The Opportunity: Reinforcement Learning (RL) techniques, where models learn through trial and error and rewards, offer another powerful avenue. RL could be particularly beneficial for discovering novel solutions or fine-tuning policies for tasks where demonstrations are hard to obtain or suboptimal.
- Future Path: Exploring how to effectively integrate RL with VLAs, especially for complex or long-horizon tasks, could unlock more dexterous and adaptive robot behaviors.
Acknowledging these areas isn’t a critique but rather an exciting roadmap for future research and development in the VLA space. SmolVLA lays a strong foundation, and these “limitations” are essentially invitations for the community to build even more capable and versatile robotic intelligence.
Quick Recap
We’ve journeyed through the exciting world of SmolVLA, uncovering how this compact yet powerful model is making advanced robotics more accessible. Here are the key takeaways:
- Small but Mighty: SmolVLA is a ~450M parameter Vision-Language-Action model designed for efficiency, allowing it to run on consumer-grade GPUs without sacrificing significant performance compared to much larger models.
- Smart Architecture: Its strength lies in intelligent design choices, including leveraging the pre-trained SmolVLM-2, efficient visual processing, layer skipping for faster inference, and a flow-matching action expert with interleaved attention for smooth, continuous actions.
- Community-Powered Learning: SmolVLA is pretrained on a diverse collection of open, community-driven datasets, which significantly boosts its generalization capabilities and real-world performance. Standardization techniques help manage the inherent variability in such datasets.
- Accessibility and Openness: By being open-source and designed for affordability, SmolVLA aims to democratize VLA research and development, empowering a wider range of enthusiasts, students, and researchers.
Conclusion
Remember that robotics enthusiast we met at the beginning, dreaming of building intelligent robots without needing a supercomputing lab? With SmolVLA, that dream is now much closer to reality. We’ve seen how its clever design and reliance on community knowledge have culminated in a Vision-Language-Action model that punches well above its weight, offering a pathway to sophisticated robotics on hardware many of us already own.
The true value of SmolVLA isn’t just in its technical specifications, but in the doors it opens. It’s a tool that invites experimentation, a platform for learning, and a contributor to a more open and collaborative robotics ecosystem. Whether you’re looking to understand how robots can interpret and act upon visual and linguistic commands, or you’re ready to start your own robotics project, SmolVLA provides a robust and efficient starting point. The journey of AI in robotics is ever-evolving, and with innovations like SmolVLA, more of us can actively participate in shaping its future.
So, what’s next? The world of VLA models is dynamic and rapidly advancing. We encourage you to stay curious, explore further, and perhaps even contribute to this exciting field. The tools are becoming more accessible, and the only limit is our imagination.
References
- hu-po: Feature Image and Inference Script Reference
- SmolVLA: A Vision-Language-Action Model Paper
- SmolVLA HF Article



100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning