SigLIP-2 represents a significant step forward in the development of multilingual vision-language encoders, bringing enhanced semantic understanding, localization, and dense feature extraction capabilities. Built on the foundations of SigLIP, this
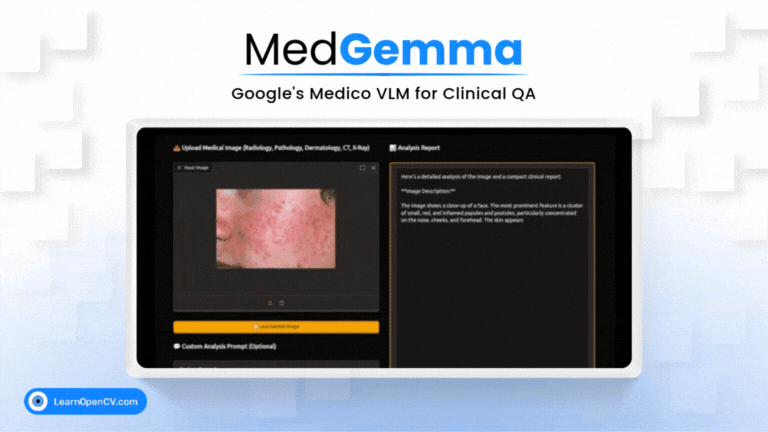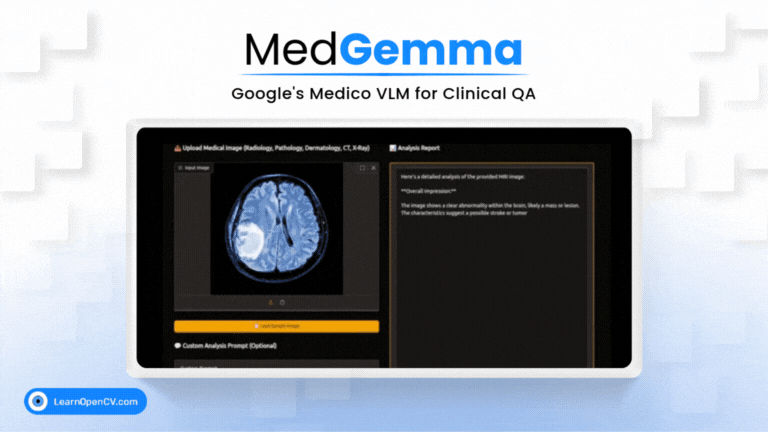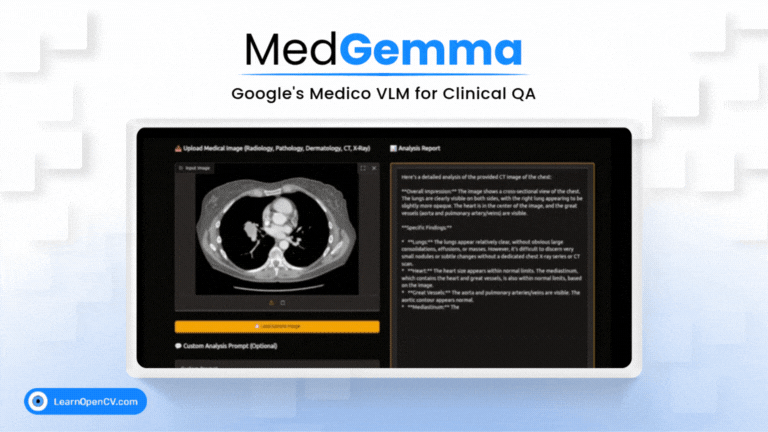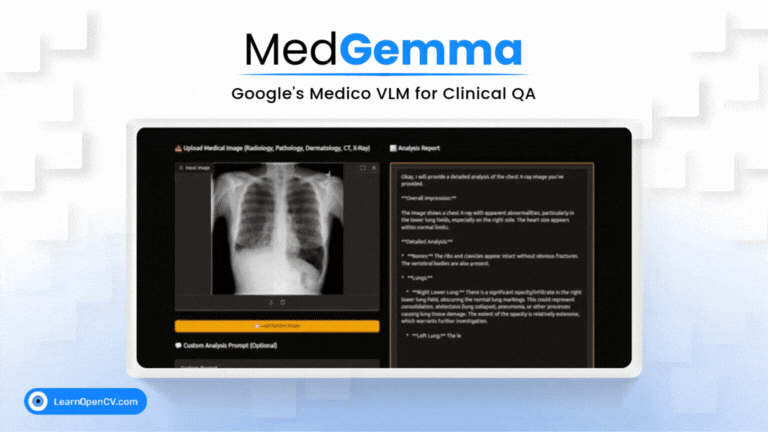
Imagine an AI co-pilot for every clinician, capable of understanding both complex medical images and dense clinical text. That's the promise of MedGemma, Google's new Vision-Language Model specifically trained for
Traditional Optical Character Recognition (OCR) systems are primarily designed to extract plain text from scanned documents or images. While useful, such systems often ignore semantic structure, layout, and visual cues
To develop AI systems that are genuinely capable in real-world settings, we need models that can process and integrate both visual and textual information with high precision. This is the