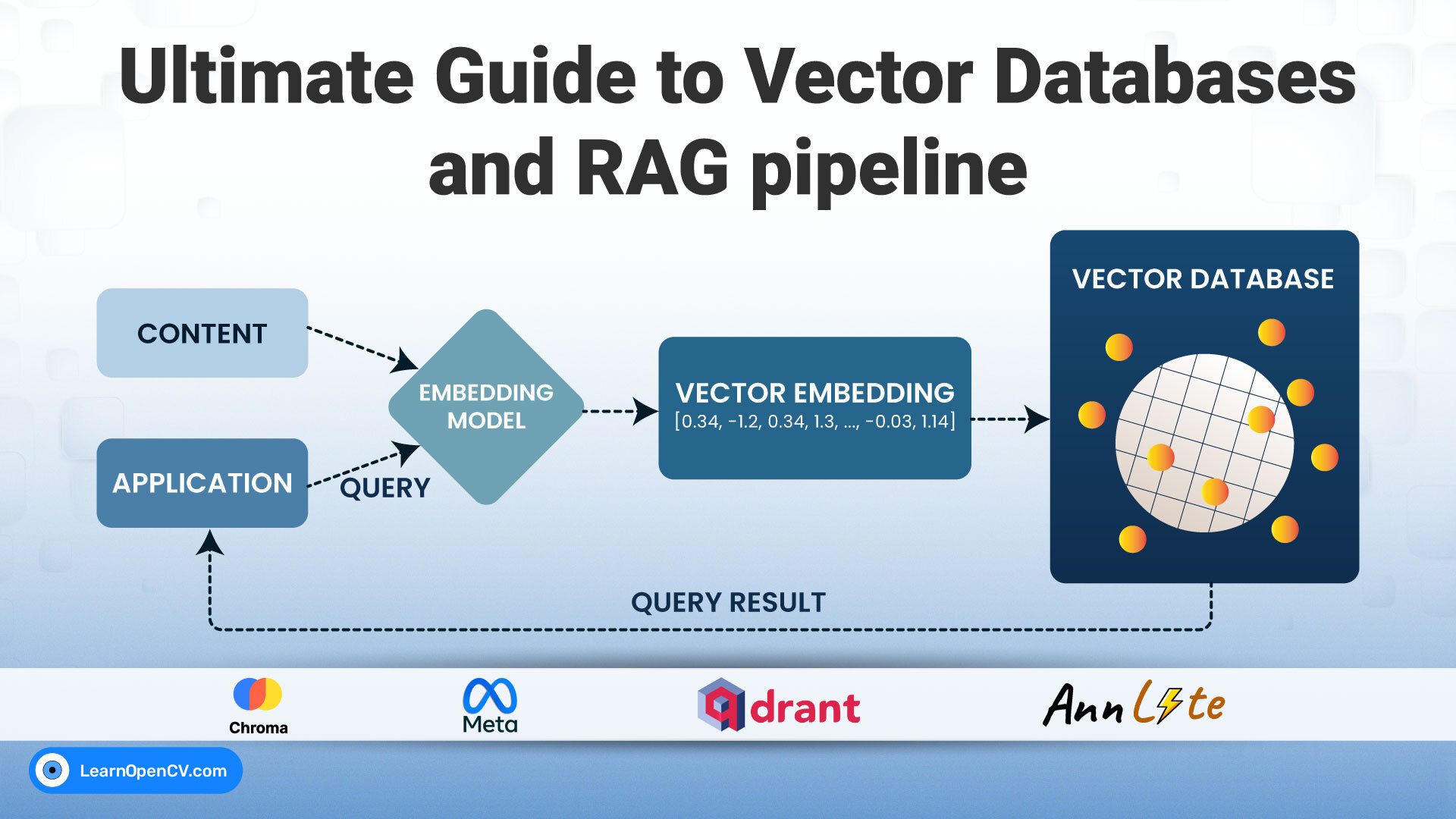
Processing long documents with VLMs or LLMs poses a fundamental challenge: input size exceeds context limits. Even with GPUs, as large as 12 GB can barely process 3-4 pages at
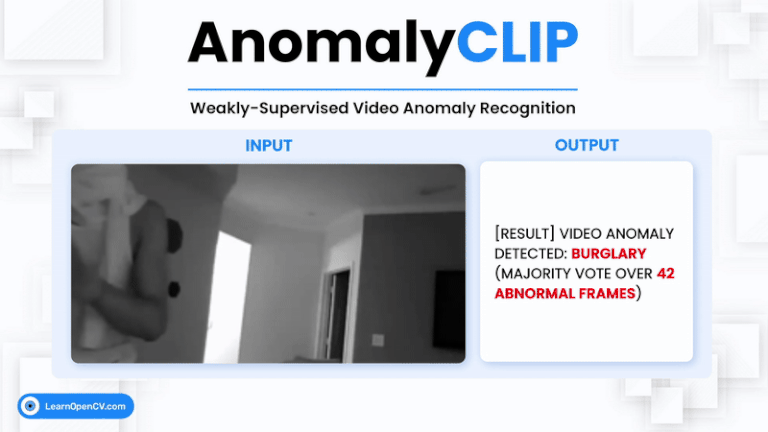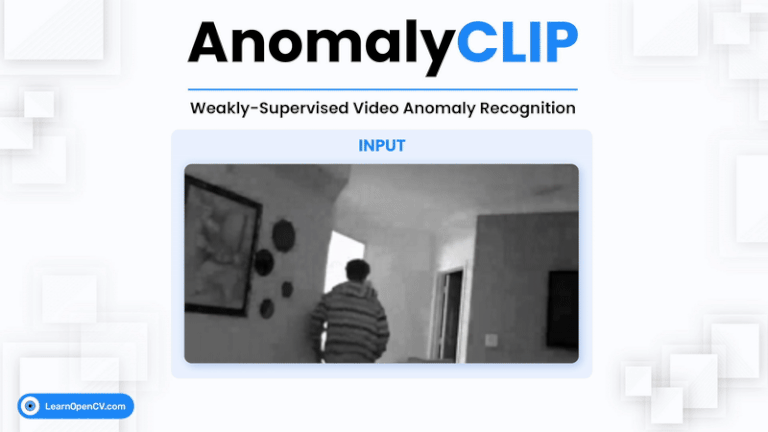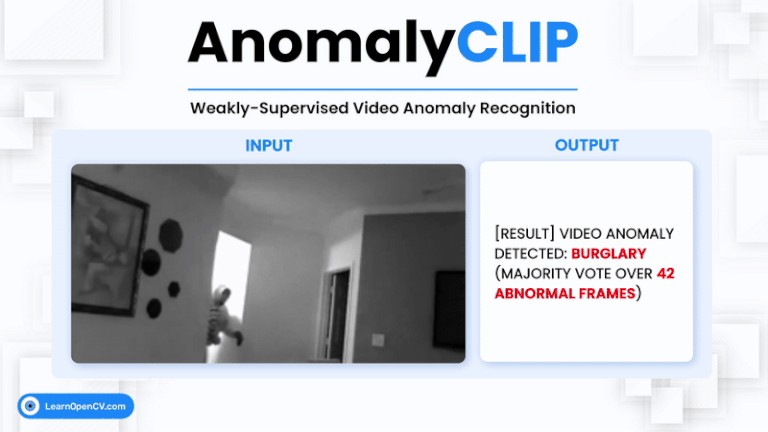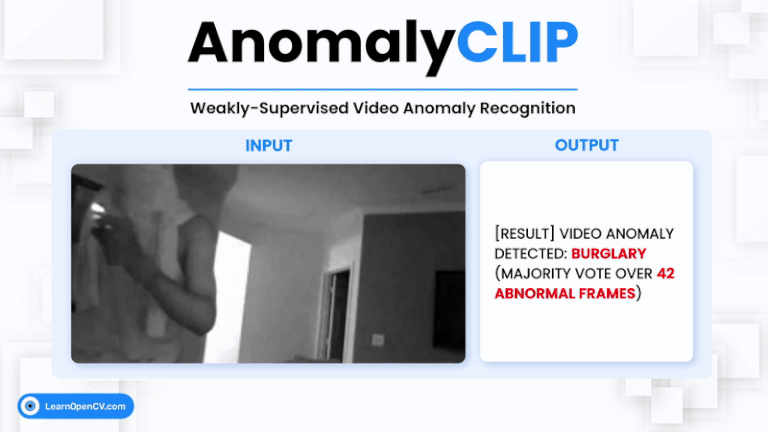
Video Anomaly Detection (VAD) is one of the most challenging problems in computer vision. It involves identifying rare, abnormal events in videos – such as burglary, fighting, or accidents –
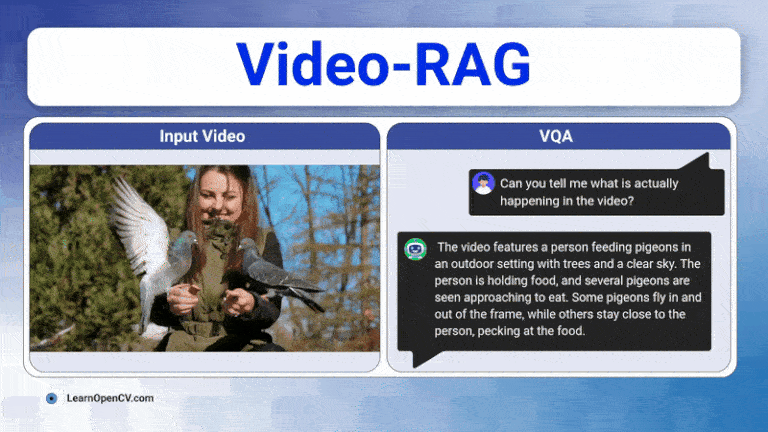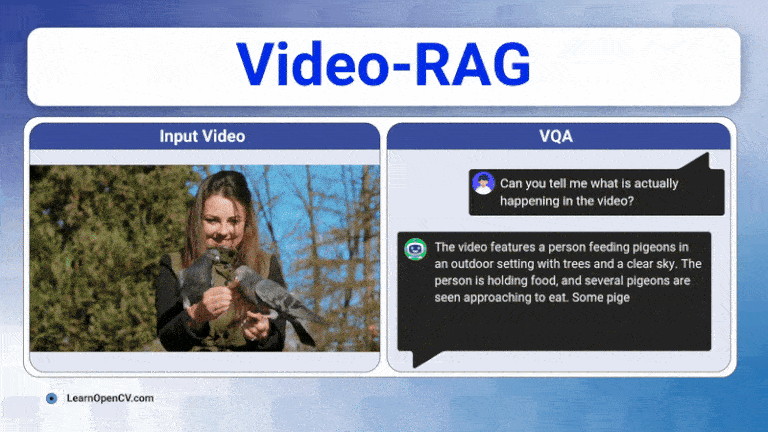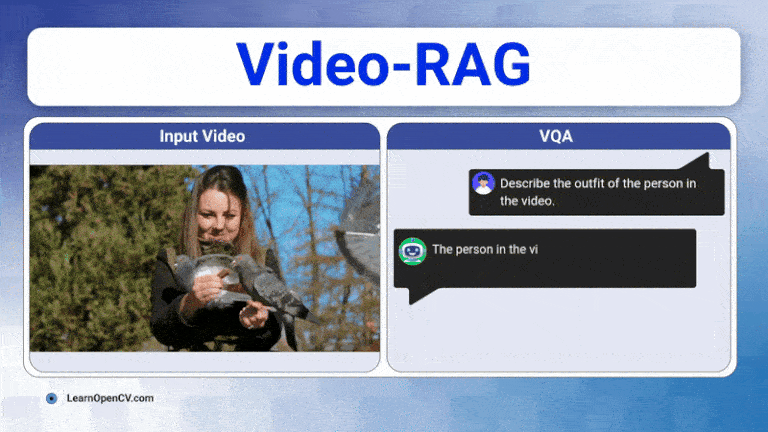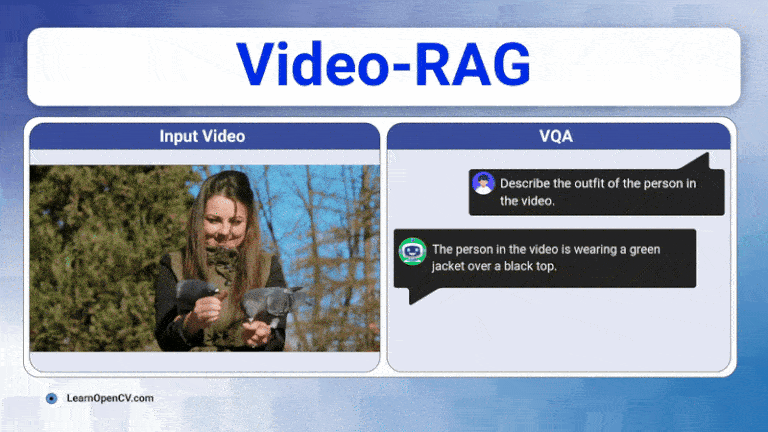
Learn how Video-RAG boosts training-free and low-compute long-video understanding by pairing OCR, ASR, and open-vocabulary detection with any long-video LVLMs.
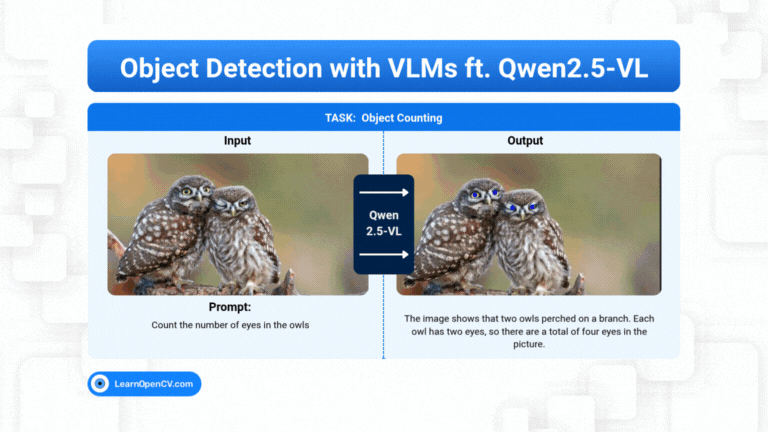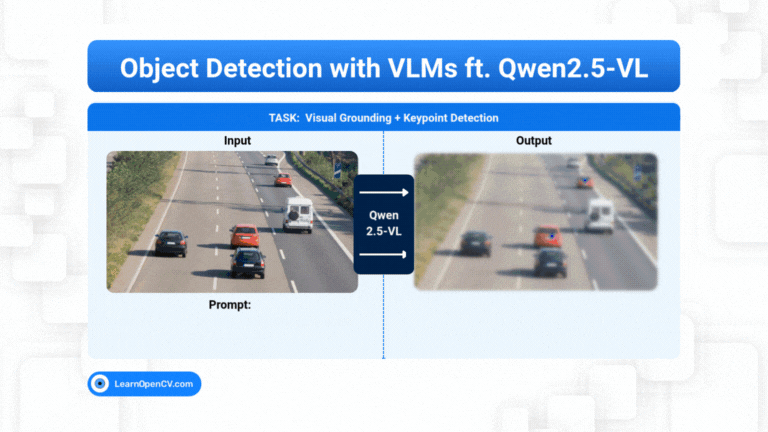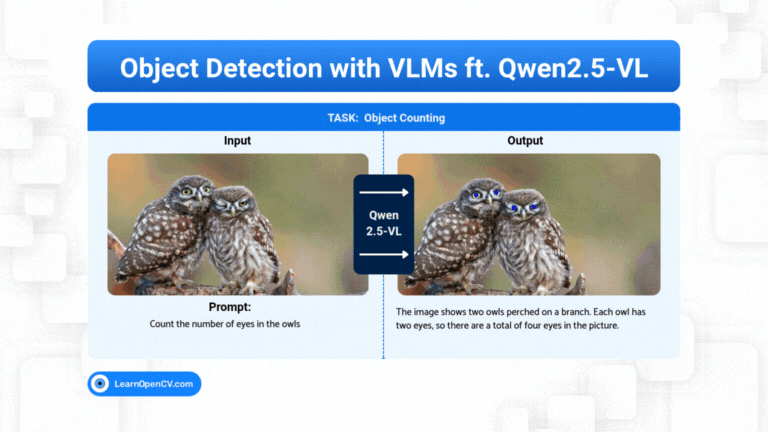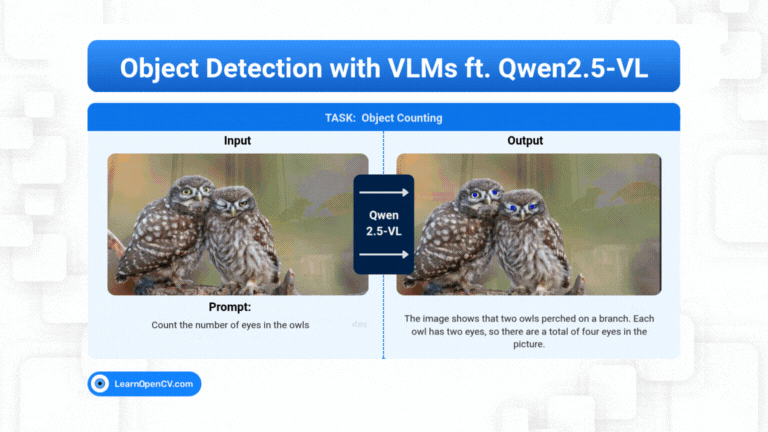
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
SimLingo is a remarkable model that combines autonomous driving, language understanding, and instruction-aware control—all in one unified, camera-only framework. It not only delivered top rankings on CARLA Leaderboard 2.0 and
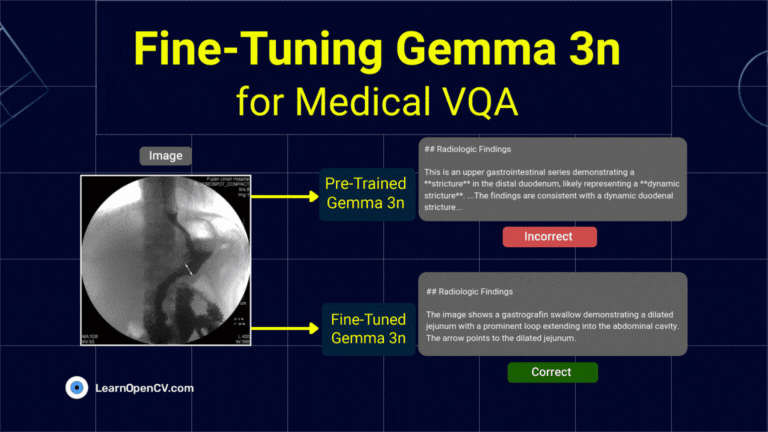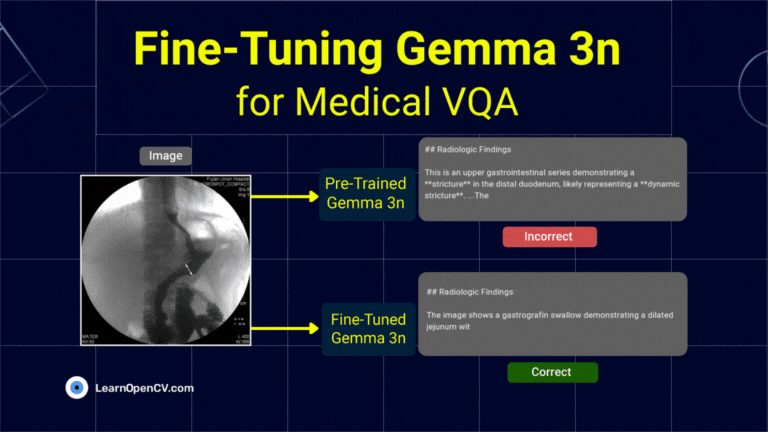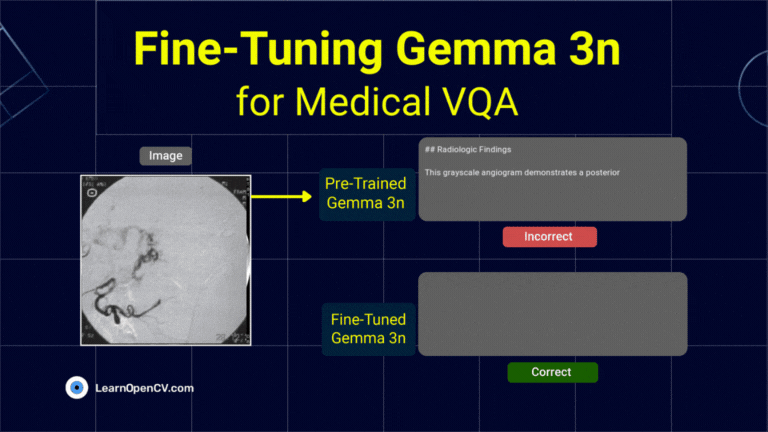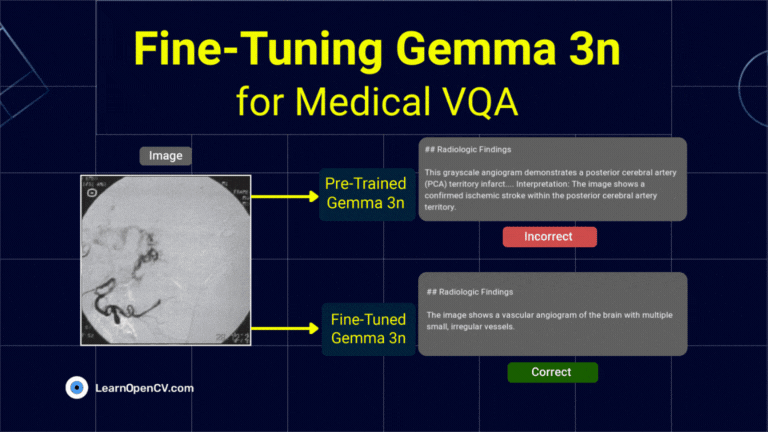
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
Developing intelligent agents, using LLMs like GPT-4o, Gemini, etc., that can perform tasks requiring multiple steps, adapt to changing information, and make decisions is a core challenge in AI development.
Zero-shot anomaly detection (ZSAD) is a vital problem in computer vision, particularly in real-world scenarios where labeled anomalies are scarce or unavailable. Traditional vision-language models (VLMs) like CLIP fall short