Learn what it really takes to run LLMs on an 8 GB Jetson Orin Nano, covering setup, failures, memory tuning, and a practical comparison between vLLM and llama.cpp. An article
Naive Transformers is good for lab experiments, but not for production. Check out what are the major problems associated with Autoregressive inference. In this post, we will cover how modern
Discover VideoRAG, a framework that fuses graph-based reasoning and multi-modal retrieval to enhance LLMs' ability to understand multi-hour videos efficiently.
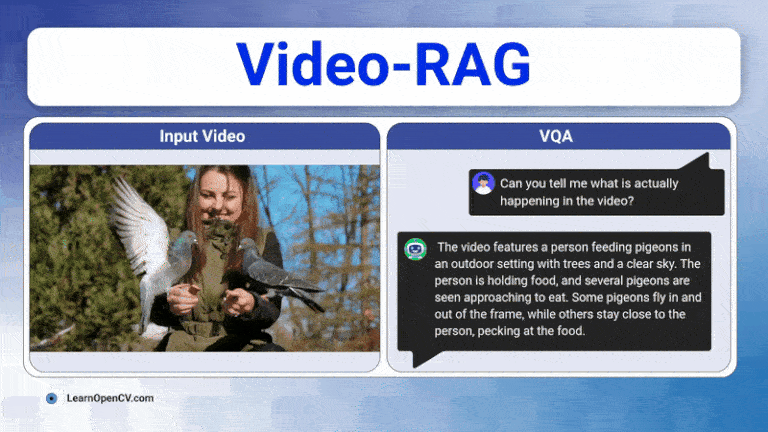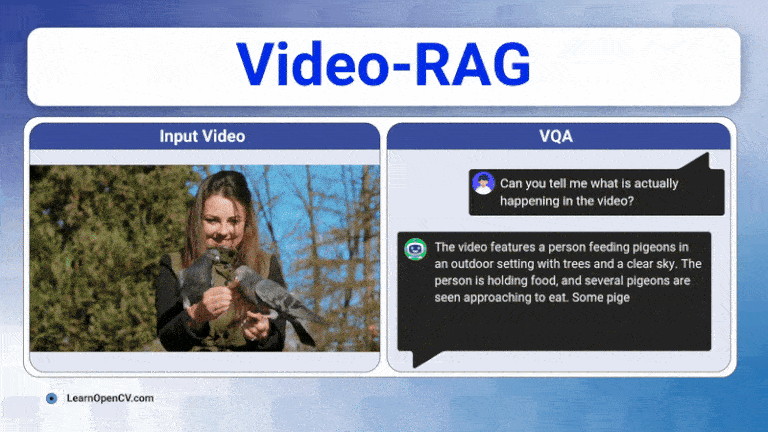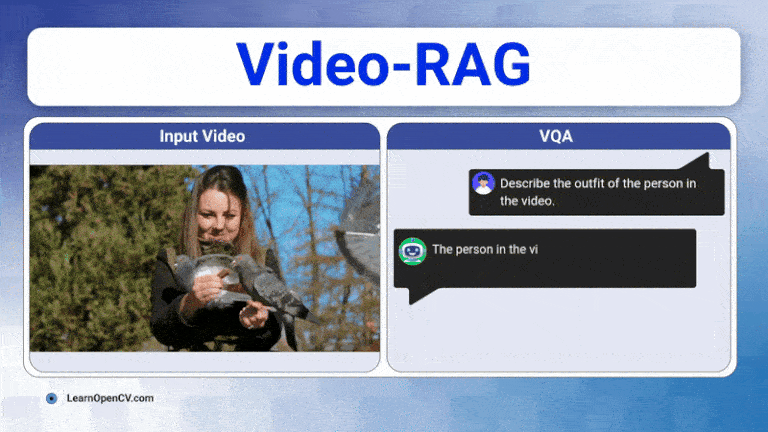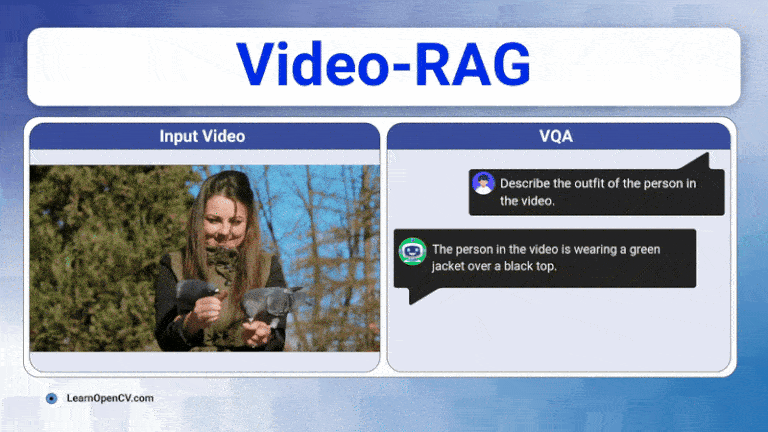
Learn how Video-RAG boosts training-free and low-compute long-video understanding by pairing OCR, ASR, and open-vocabulary detection with any long-video LVLMs.
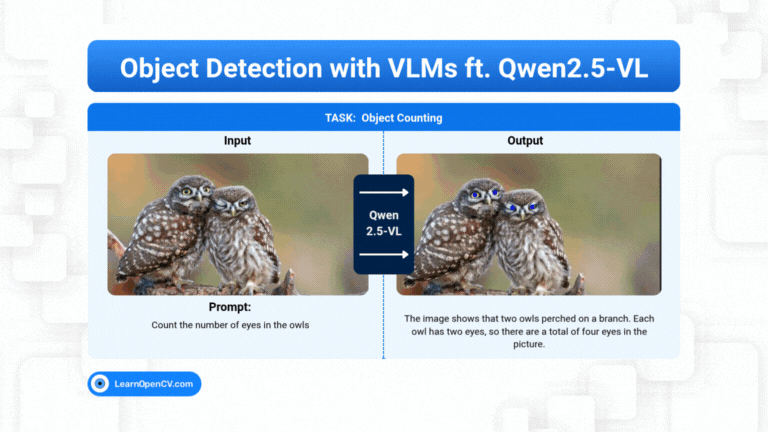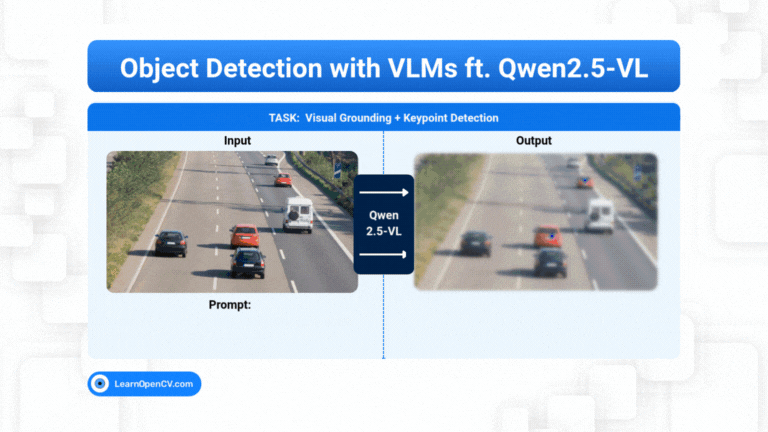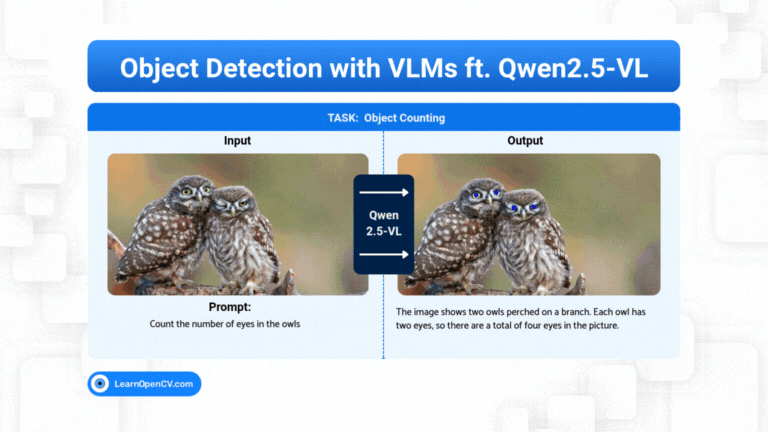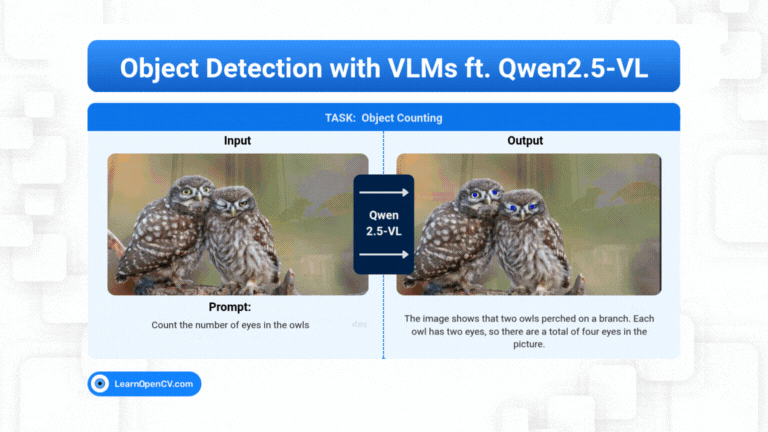
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
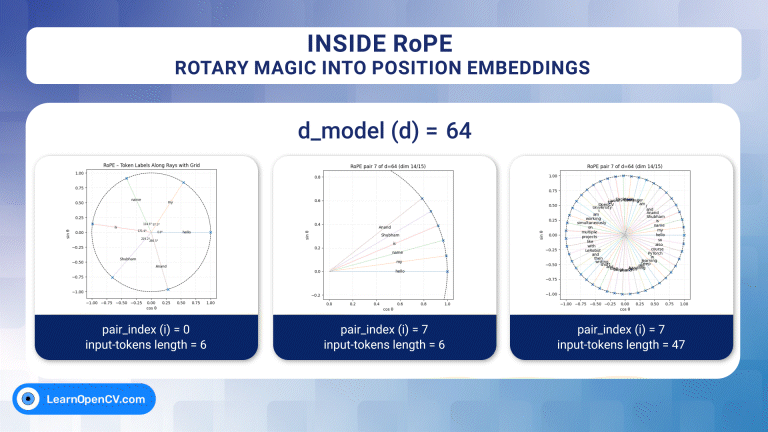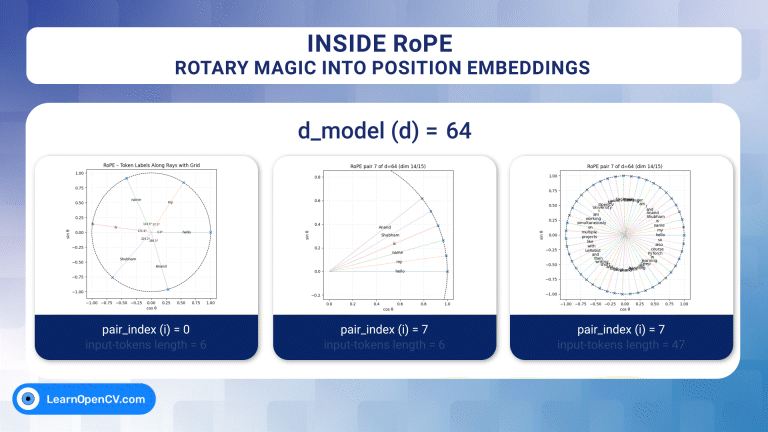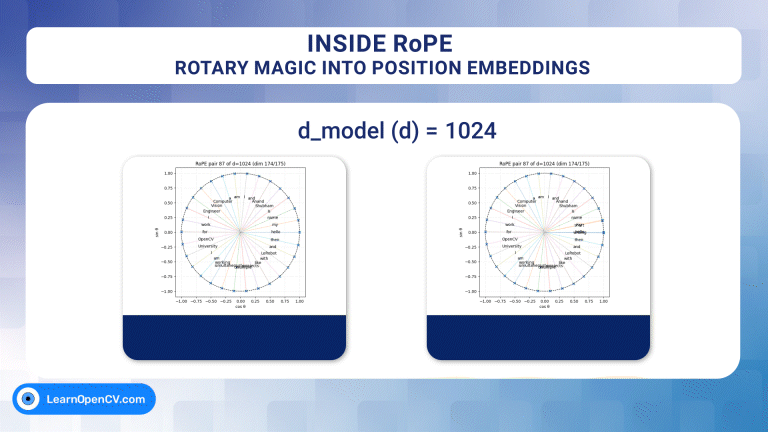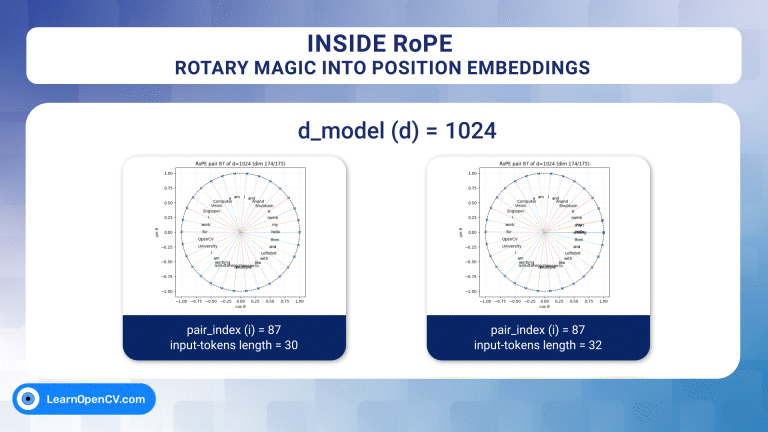
In the groundbreaking 2017 paper “Attention Is All You Need”, Vaswani et al. introduced Sinusoidal Position Embeddings to help Transformers encode positional information, without recurrence or convolution. This elegant, non-learned
Self-attention, the beating heart of Transformer architectures, treats its input as an unordered set. That mathematical elegance is also a curse: without extra signals, the model has no idea which
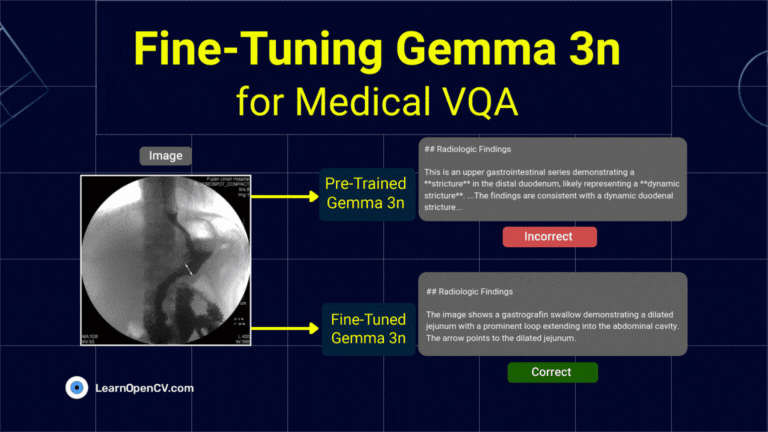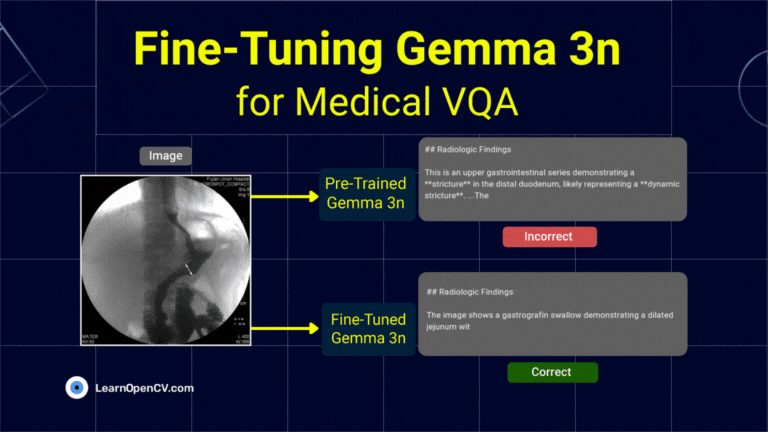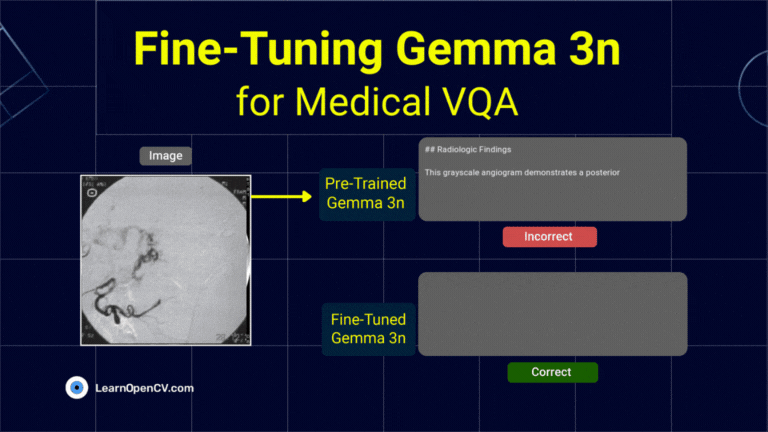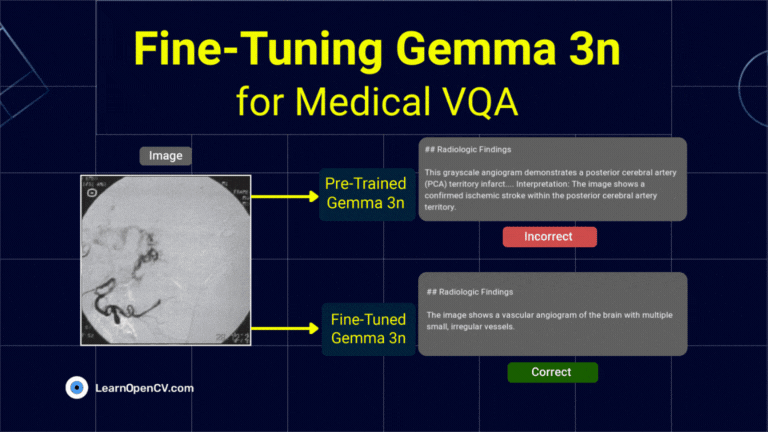
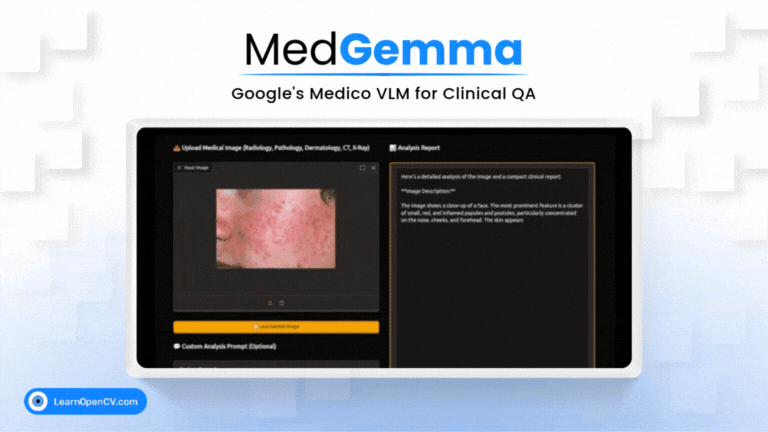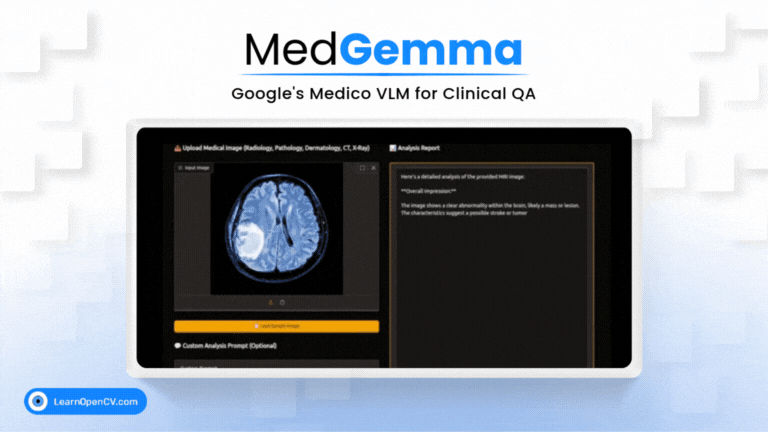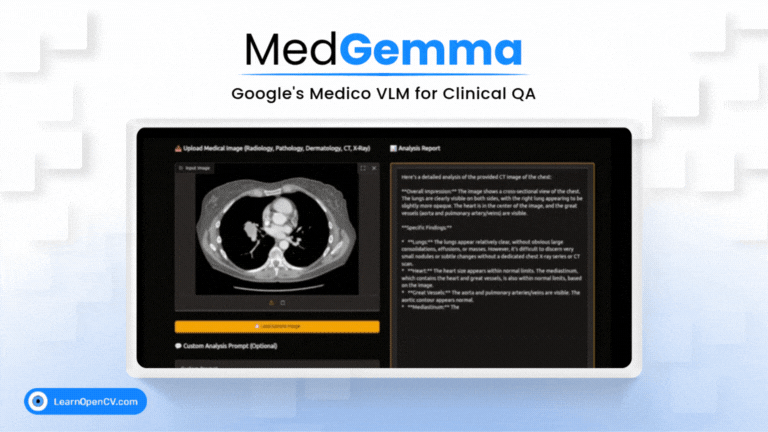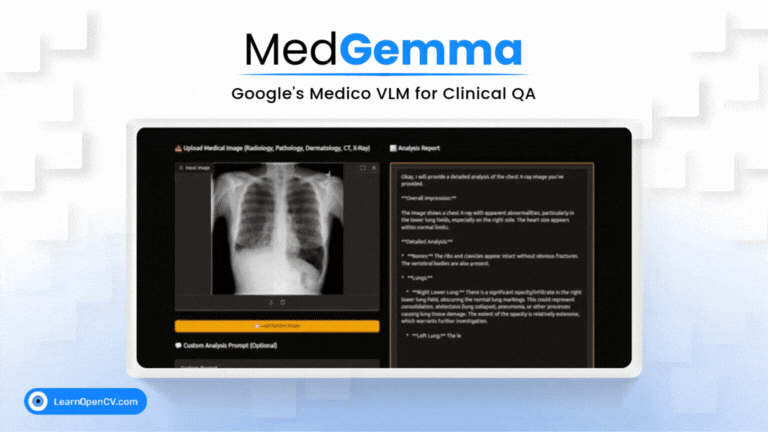
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
In the evolving landscape of open-source language models, SmolLM3 emerges as a breakthrough: a 3 billion-parameter, decoder-only transformer that rivals larger 4 billion-parameter peers on many benchmarks, while natively supporting
Developing intelligent agents, using LLMs like GPT-4o, Gemini, etc., that can perform tasks requiring multiple steps, adapt to changing information, and make decisions is a core challenge in AI development.
SigLIP-2 represents a significant step forward in the development of multilingual vision-language encoders, bringing enhanced semantic understanding, localization, and dense feature extraction capabilities. Built on the foundations of SigLIP, this
Imagine an AI co-pilot for every clinician, capable of understanding both complex medical images and dense clinical text. That's the promise of MedGemma, Google's new Vision-Language Model specifically trained for