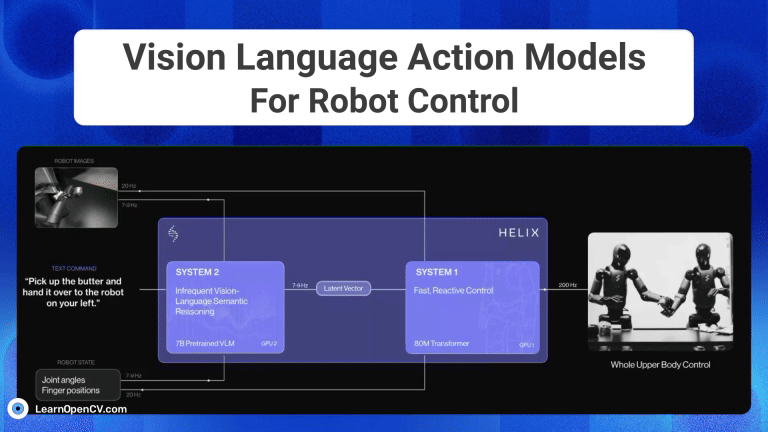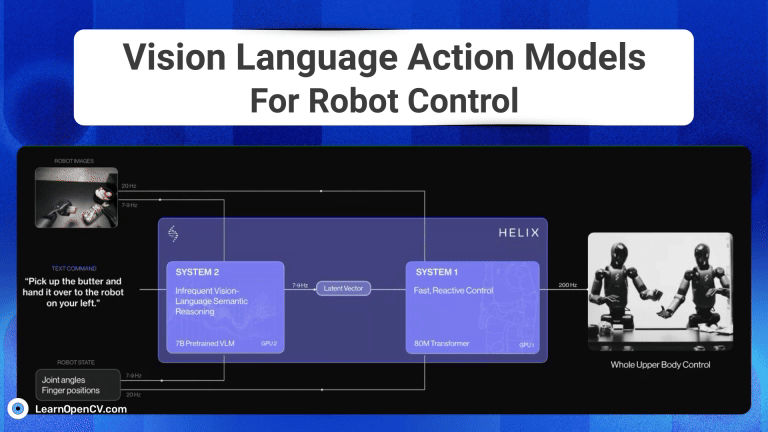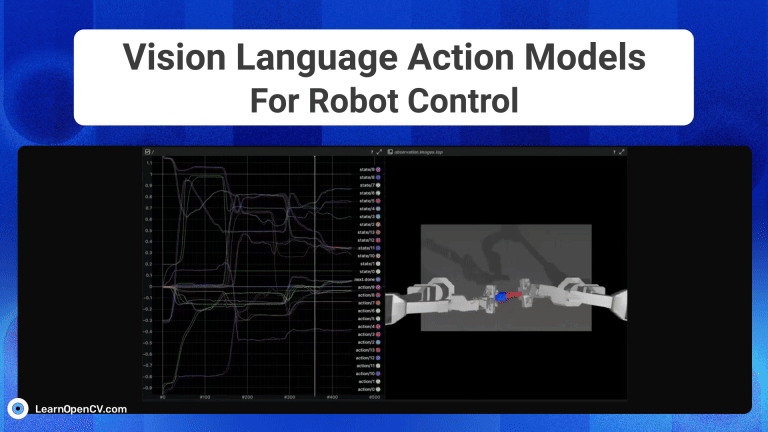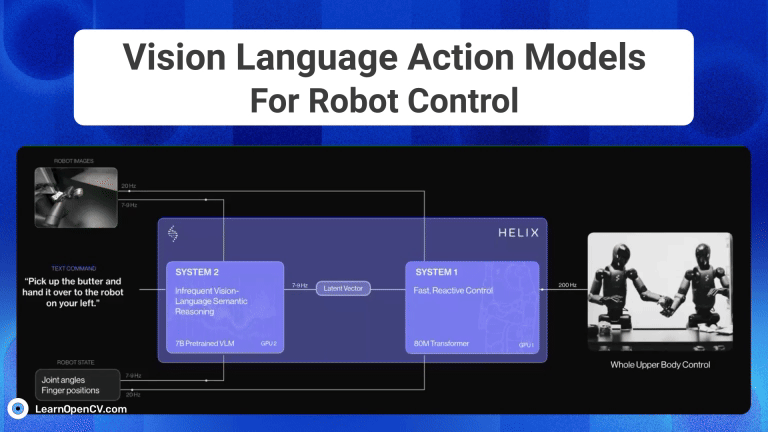
The advent of Generative AI, has fundamentally transformed robotic intelligence, enabling significant strides in how advanced humanoid robots “perceive, reason and act” in the physical world. This huge progress is
Fine-Tuning Gemma 3 allows us to adapt this advanced model to specific tasks, optimizing its performance for domain-specific applications. By leveraging QLoRA (Quantized Low-Rank Adaptation) and Transformers, we can efficiently
Gemma 3 is the latest addition to Google’s family of open models, built from the same research and technology used to create the Gemini models. It is designed to be
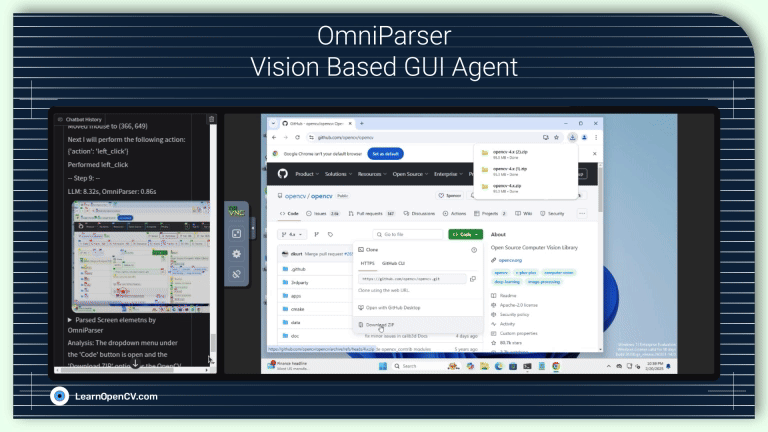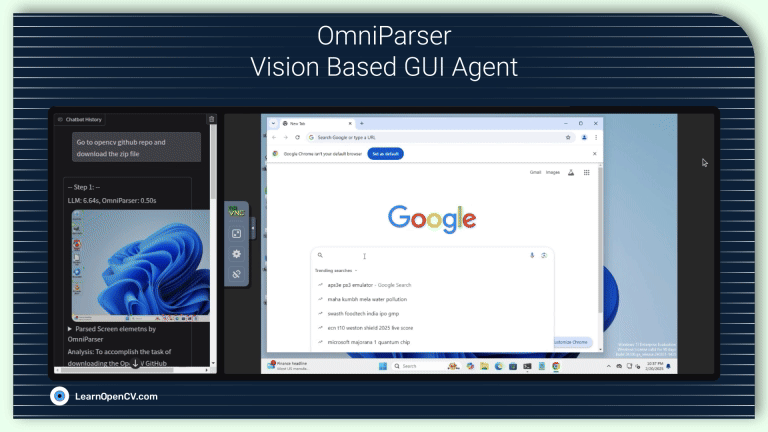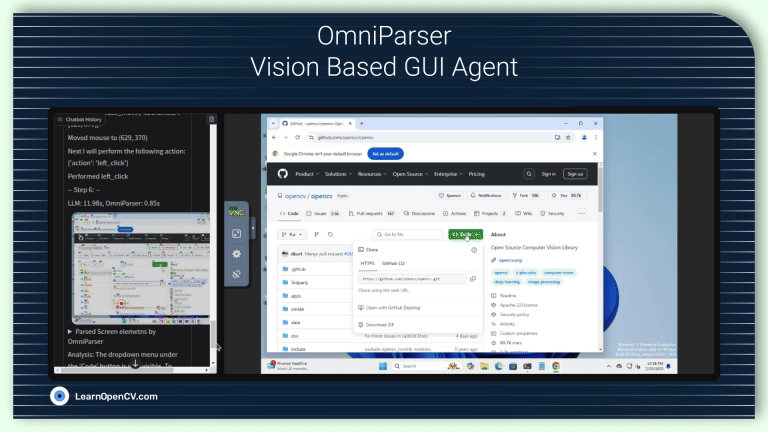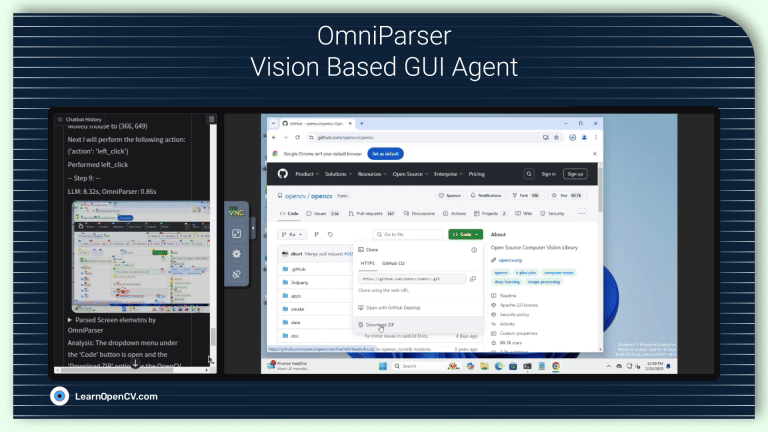
In this article, we explore OmniParser a UI screen parsing pipeline combining fine-tuned YOLO model for icon detection and Florence2 for icon recognition and icon description generation.
Molmo VLM is an open-source Vision-Language Model (VLM) showcasing exceptional capabilities in tasks like pointing, counting, VQA, and clock face recognition. Leveraging the meticulously curated PixMo dataset and a well-optimized
Performing RAG on Unstructured elements that too in complex pdfs like finance, law reports is challenging. ColPali a novel document retrieval approach achieves SOTA results with high quality retrieval. This