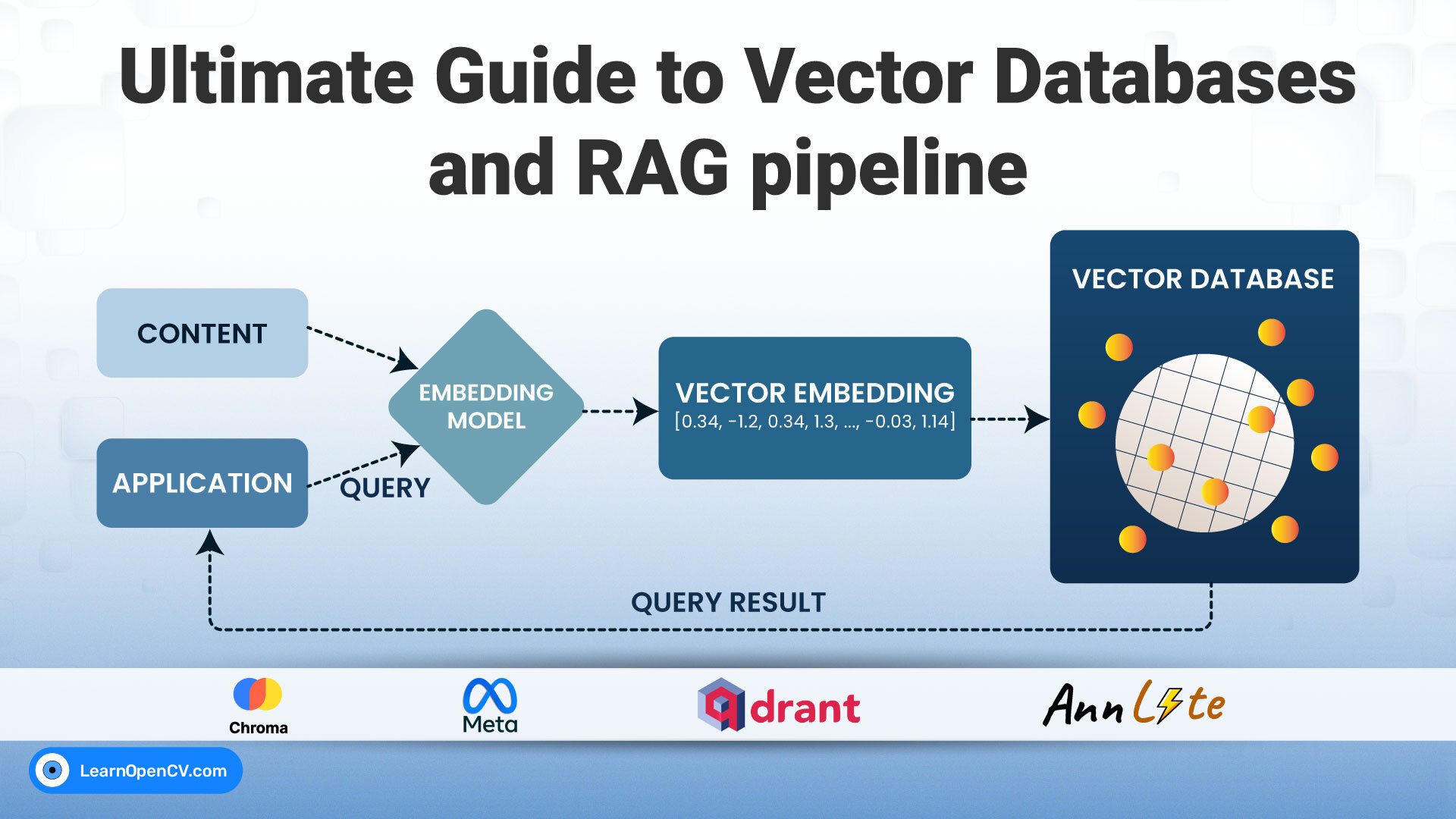
Understanding large GitHub repositories can be time-consuming. Code-Analyser tackles this problem by using an agentic, approach to parse and analyze codebases.
Naive Transformers is good for lab experiments, but not for production. Check out what are the major problems associated with Autoregressive inference. In this post, we will cover how modern
Processing long documents with VLMs or LLMs poses a fundamental challenge: input size exceeds context limits. Even with GPUs, as large as 12 GB can barely process 3-4 pages at
DeepSeek OCR Paper Explanation and Test using Transformers and vLLM Pipeline. Understanding Context Optical Compression and model architecture in depth.
Discover VideoRAG, a framework that fuses graph-based reasoning and multi-modal retrieval to enhance LLMs' ability to understand multi-hour videos efficiently.
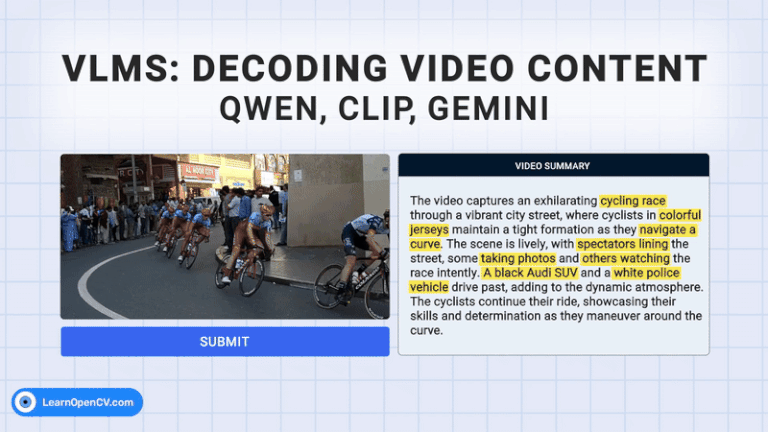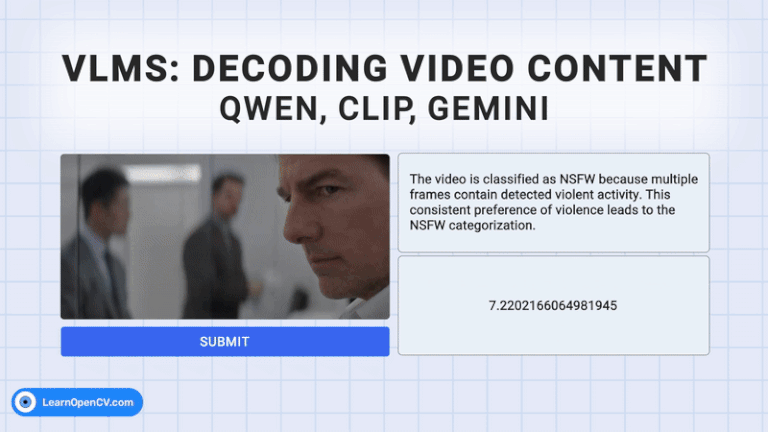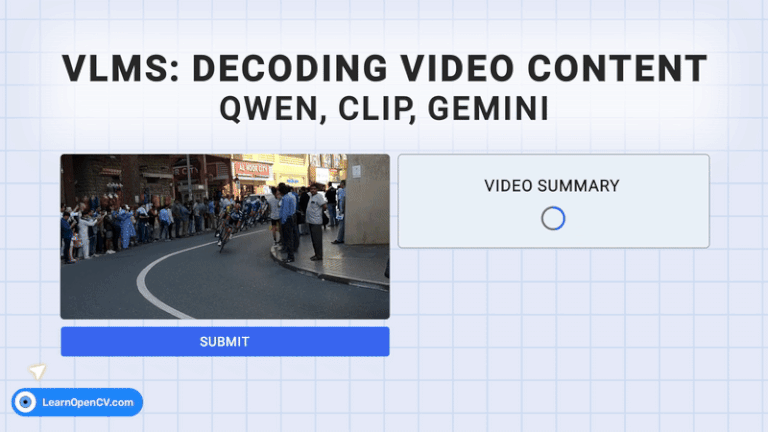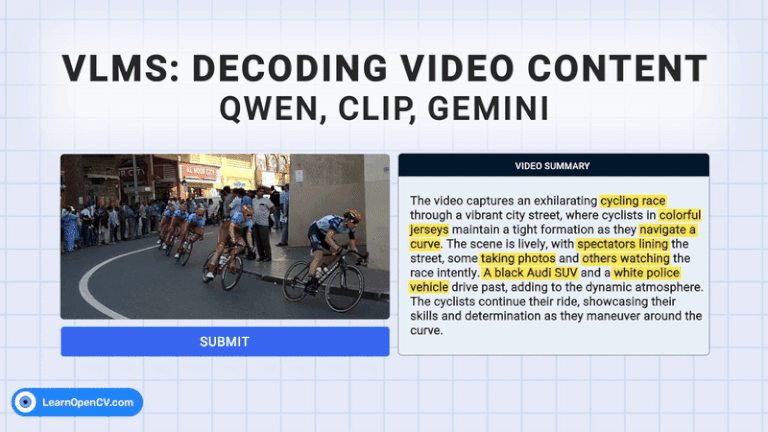
The rapid growth of video content has created a need for advanced systems to process and understand this complex data. Video understanding is a critical field in AI, where the
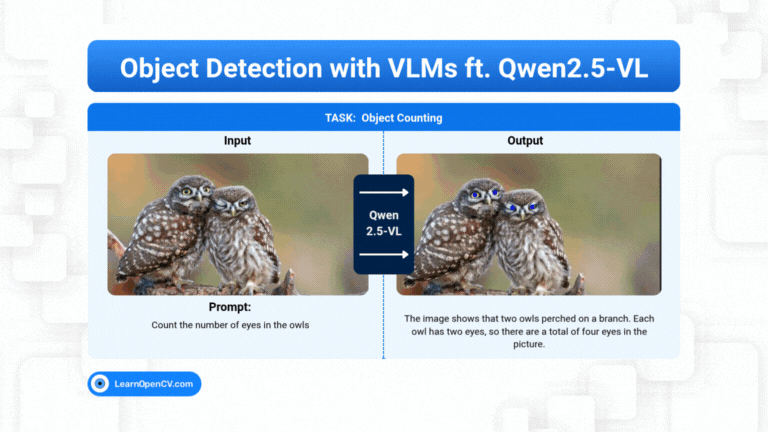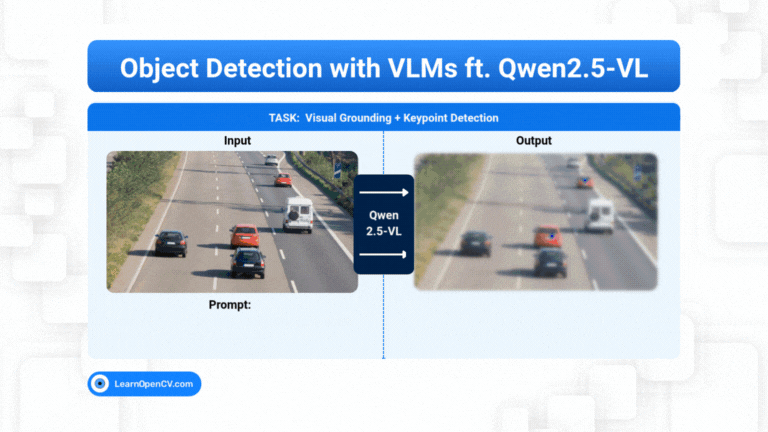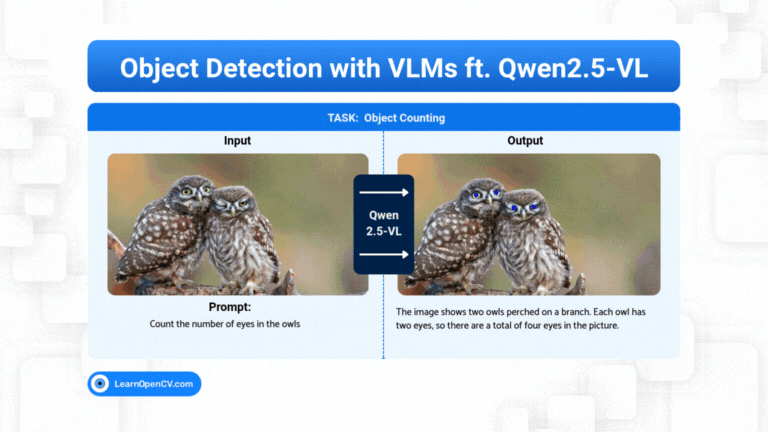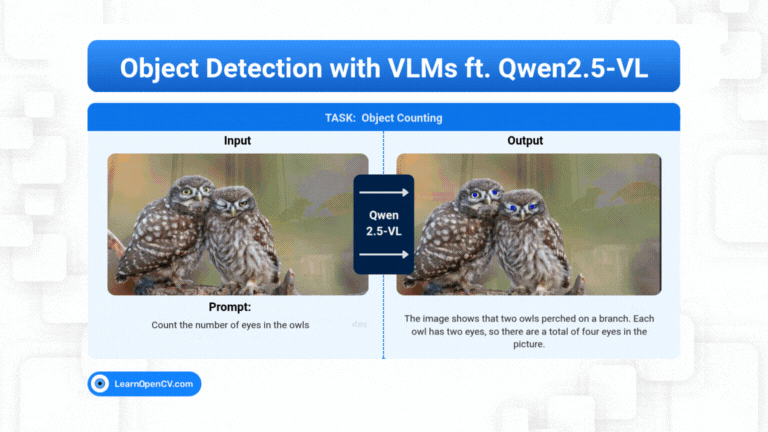
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
Welcome back to our LangGraph series! In our previous post, we explored the fundamental concepts of LangGraph by building a Visual Web Browser Agent that could navigate, see, scroll, and summarize
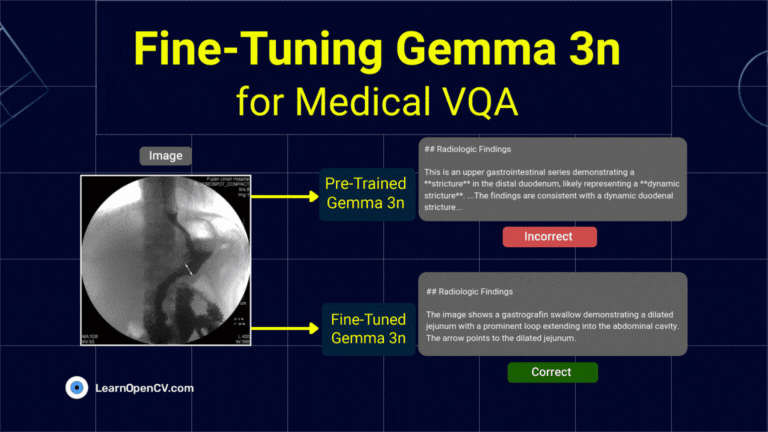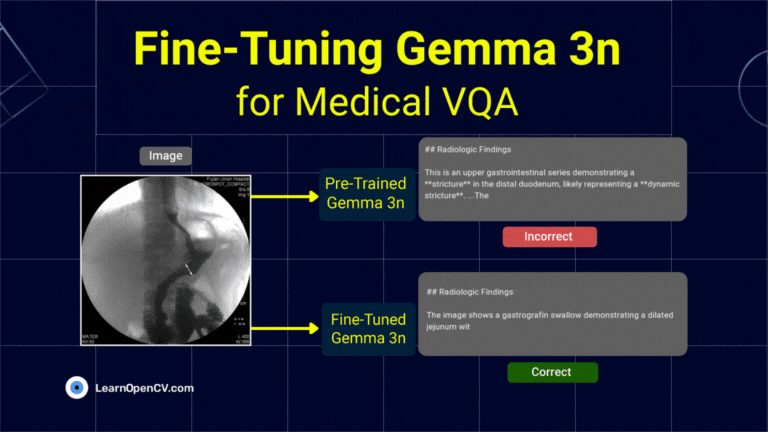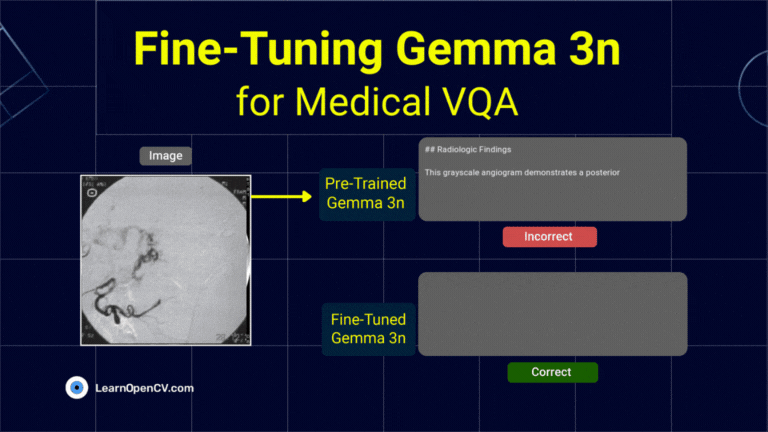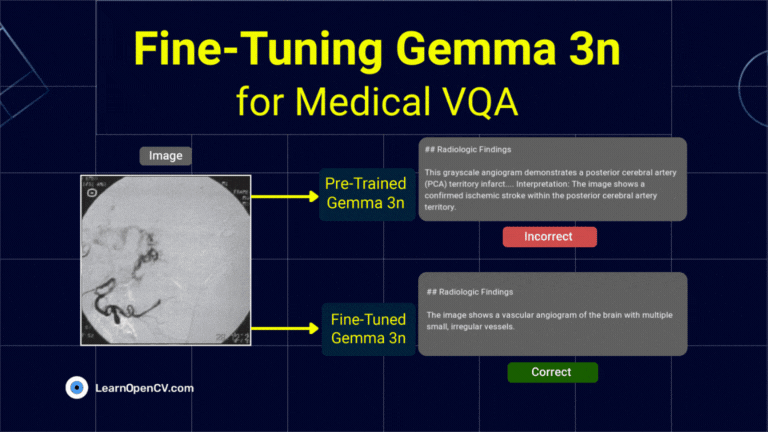
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
Developing intelligent agents, using LLMs like GPT-4o, Gemini, etc., that can perform tasks requiring multiple steps, adapt to changing information, and make decisions is a core challenge in AI development.