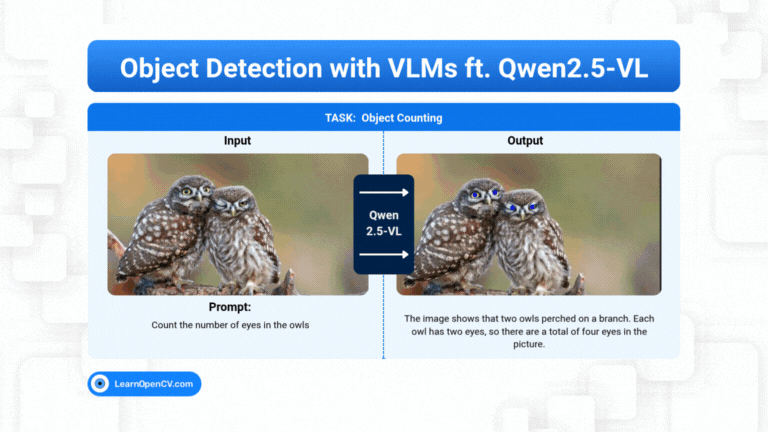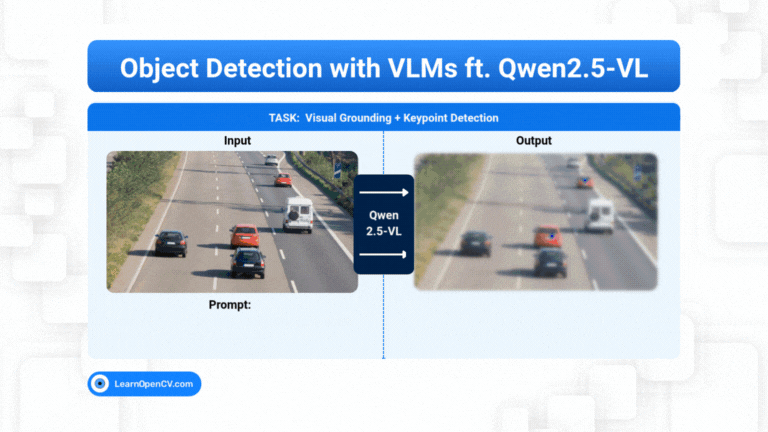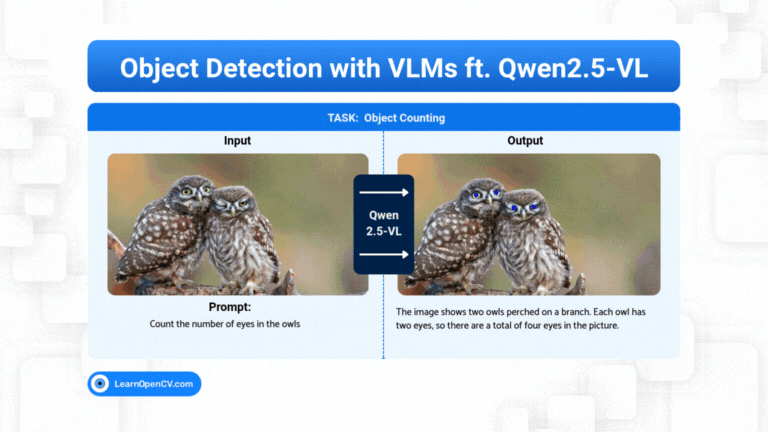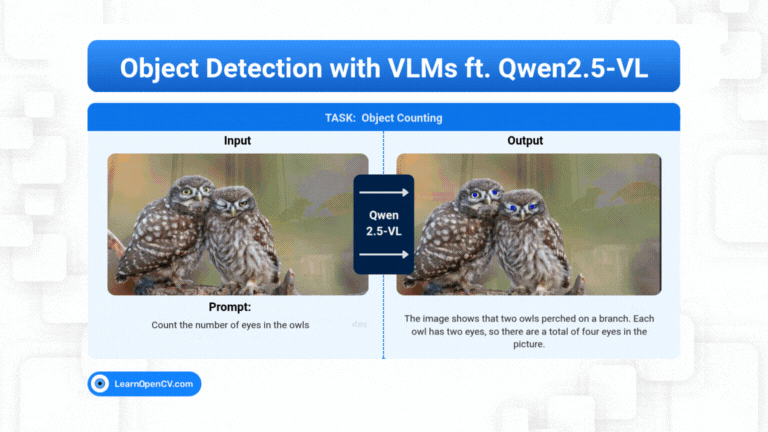
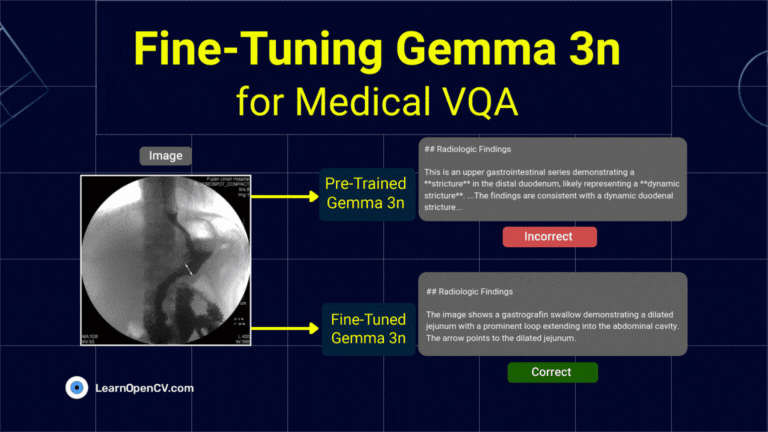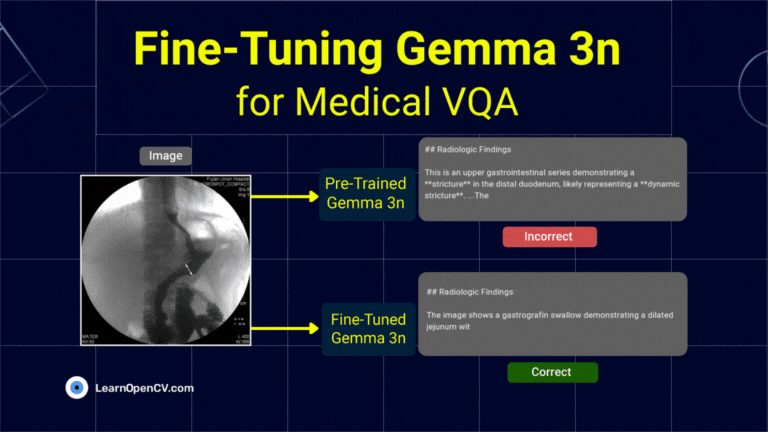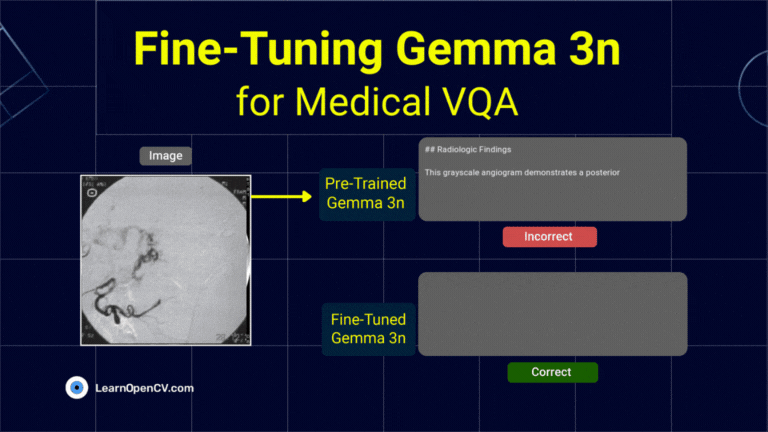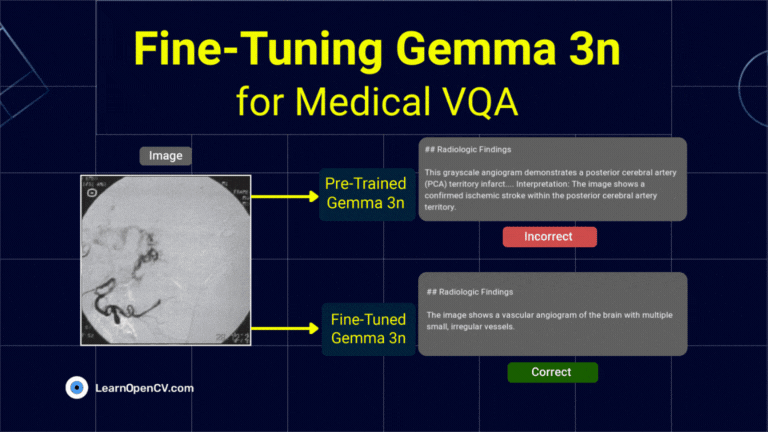
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
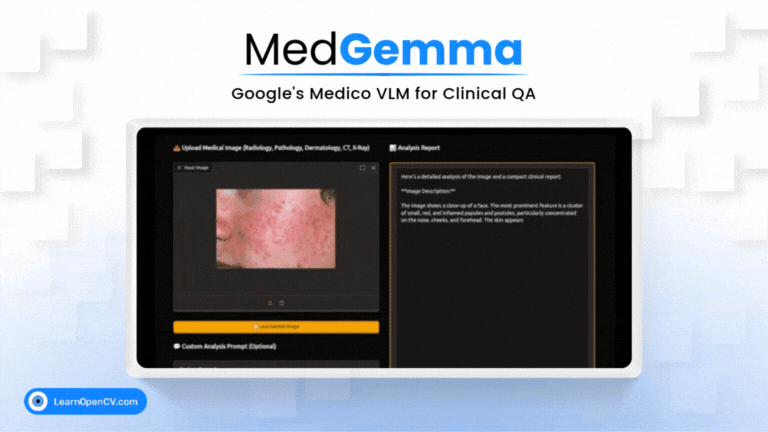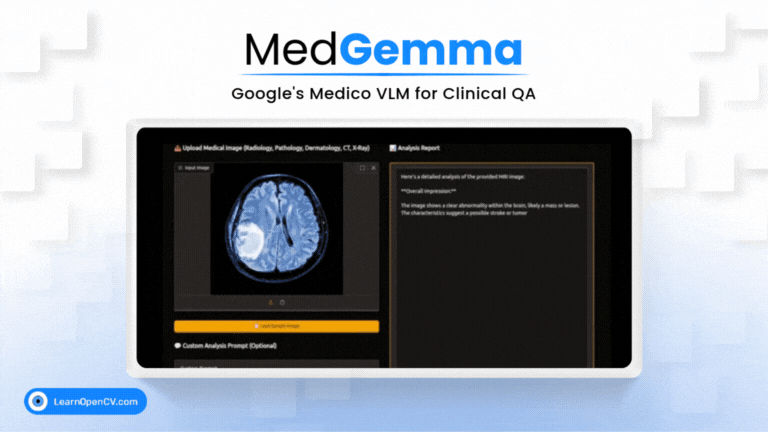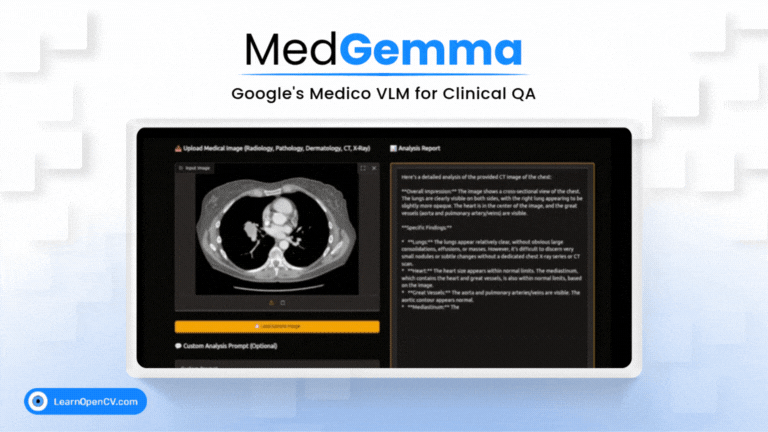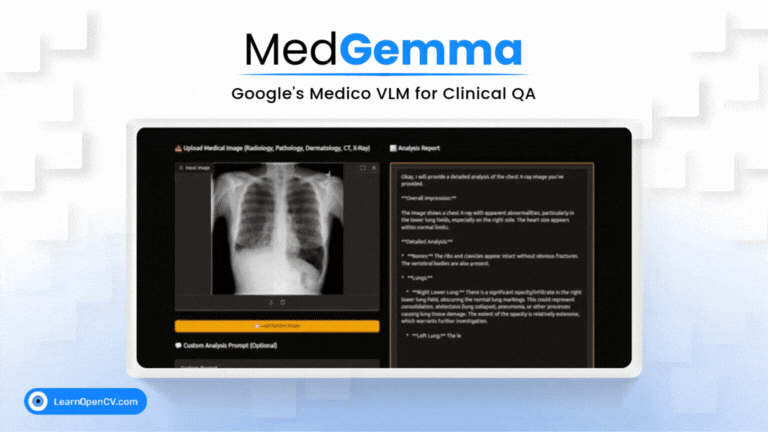
Imagine an AI co-pilot for every clinician, capable of understanding both complex medical images and dense clinical text. That's the promise of MedGemma, Google's new Vision-Language Model specifically trained for
Dive into NVIDIA's GR00T N1.5, a groundbreaking open foundation model poised to revolutionize humanoid robotics! Discover how this advanced Vision-Language-Action (VLA) model, with its smarter architecture and innovative training using
Imagine you’re a robotics enthusiast, a student, or even a seasoned developer, and you’ve been captivated by the idea of robots that can see, understand our language, and then act on that
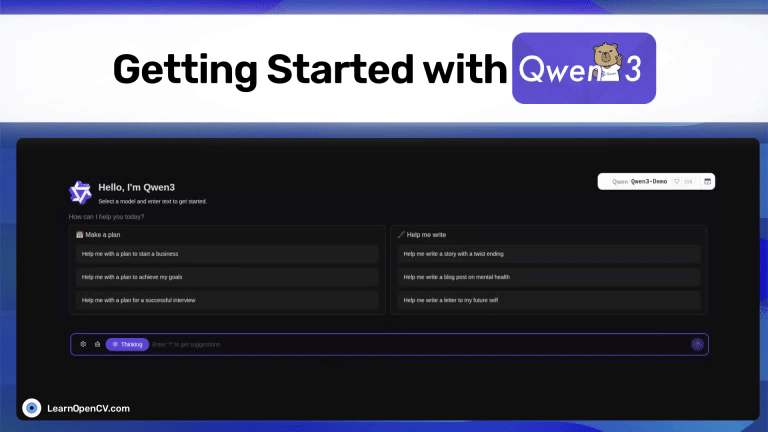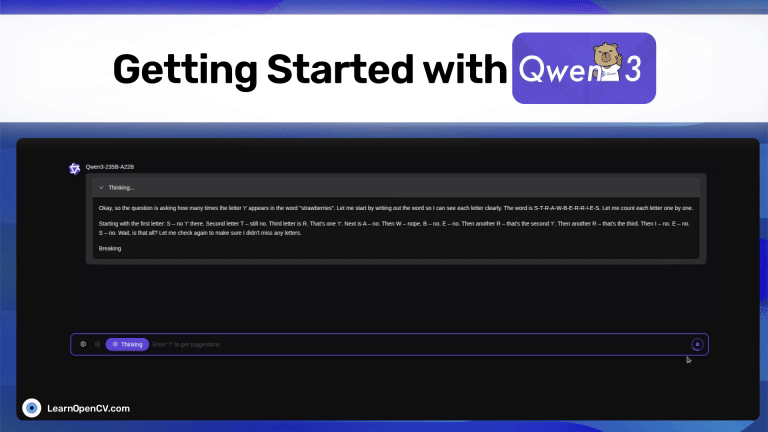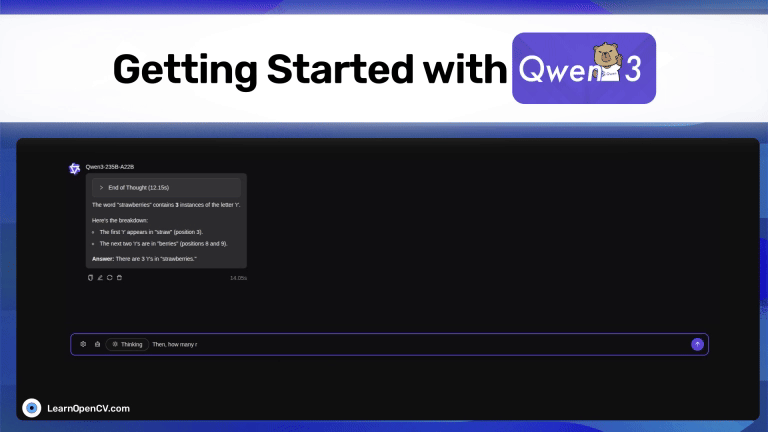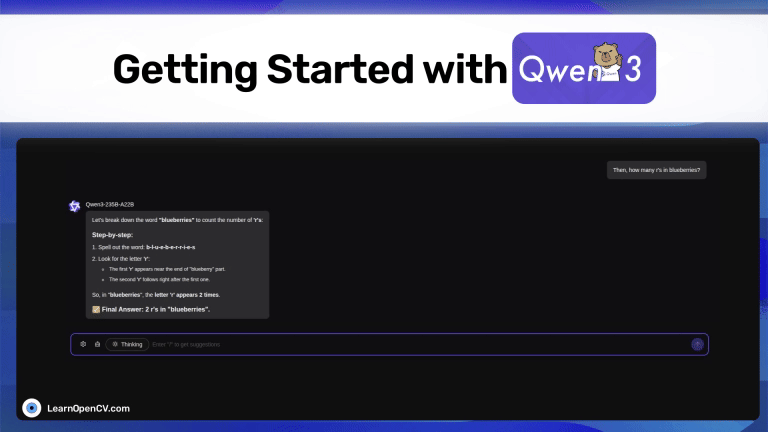
Discover Qwen3, Alibaba’s open-source thinking LLM. Switch between fast replies and chain-of-thought reasoning with 128 K context, and MoE efficiency. Learn how to use and Fine Tune.
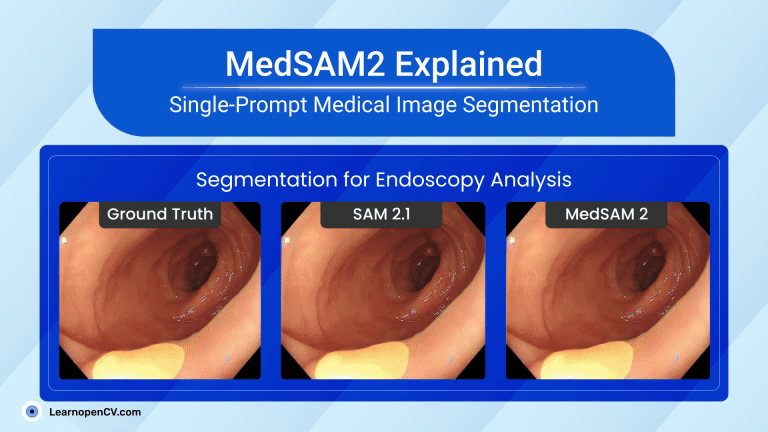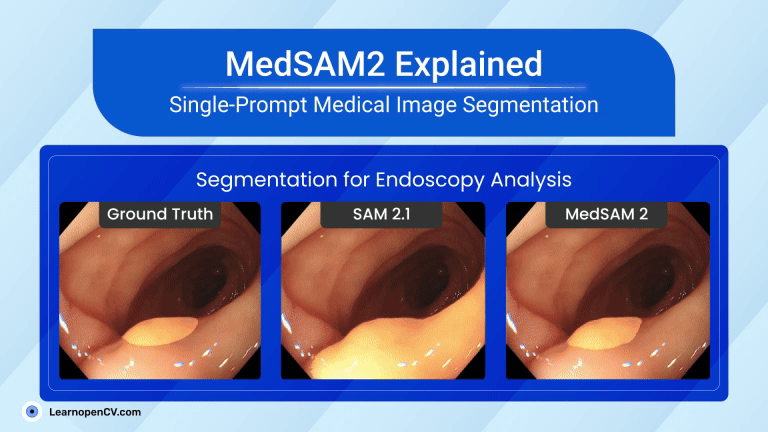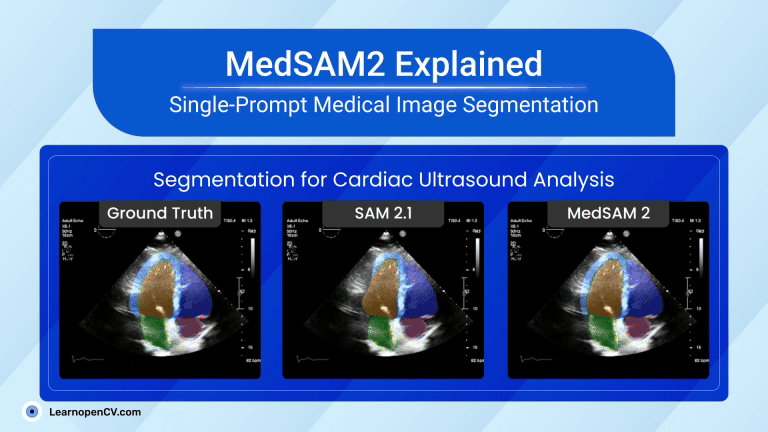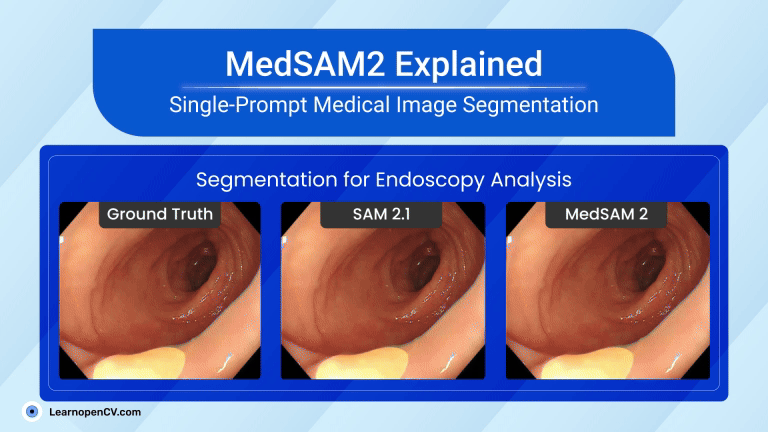
MedSAM2 brings “segment anything” power to healthcare, carving organs, tumours, and even moving heart chambers from CT, MRI, PET, and live ultrasound with a single prompt. Running in < 1
As AI systems become more specialized, getting them to work together without endless glue code is the next big challenge. That’s where Google’s A2A Protocol (Agent-to-Agent) steps in—a standardized messaging
GPT-4o image generation is a game-changer! With native support in ChatGPT, you can now create stunning visuals from text prompts, refine them, and explore styles like Studio Ghibli or photorealism.
Imagine you have multiple warehouses in different places where you don’t have time to monitor everything at a time, and you can’t afford a lot of computes due to their
A comprehensive step-by-step guide on fine-tuning RetinaNet using PyTorch to achieve 79% accuracy on wildlife detection tasks. In this tutorial, we dive deep into RetinaNet’s architecture, explain the benefits of
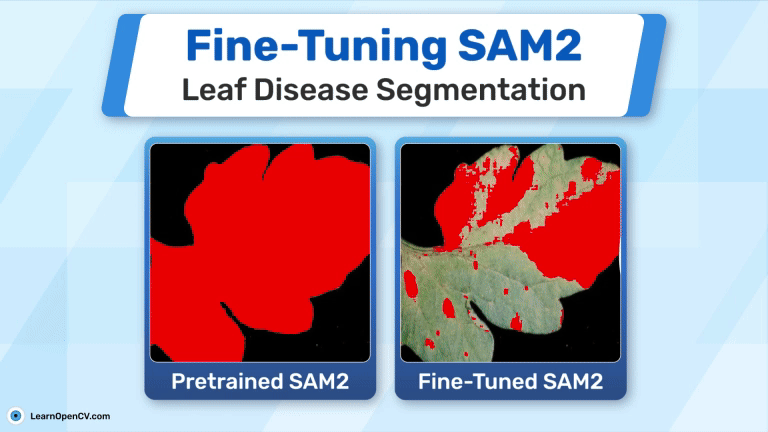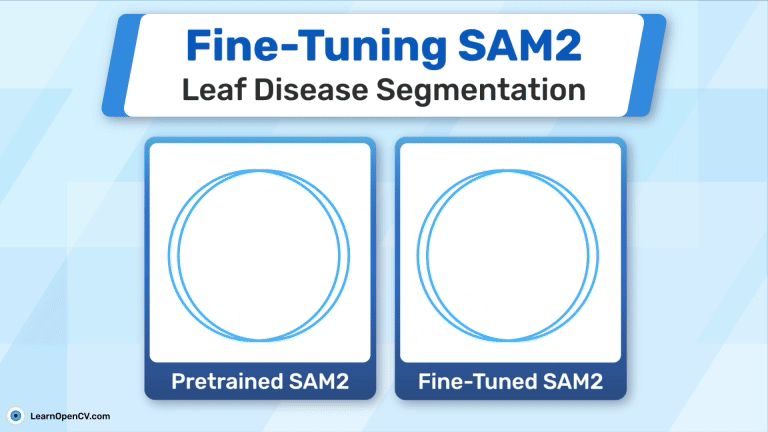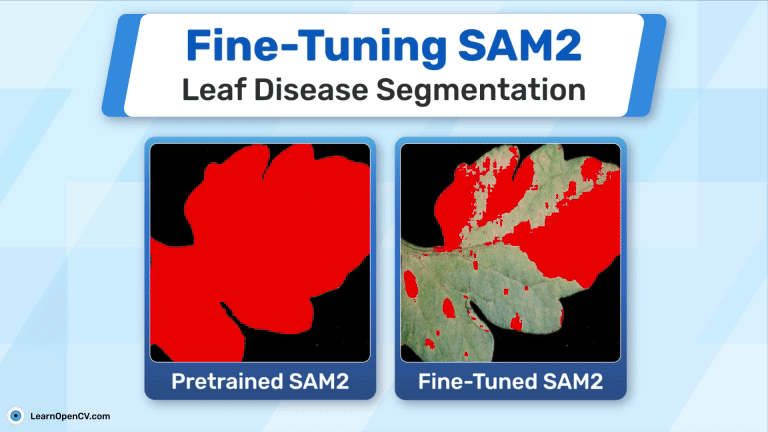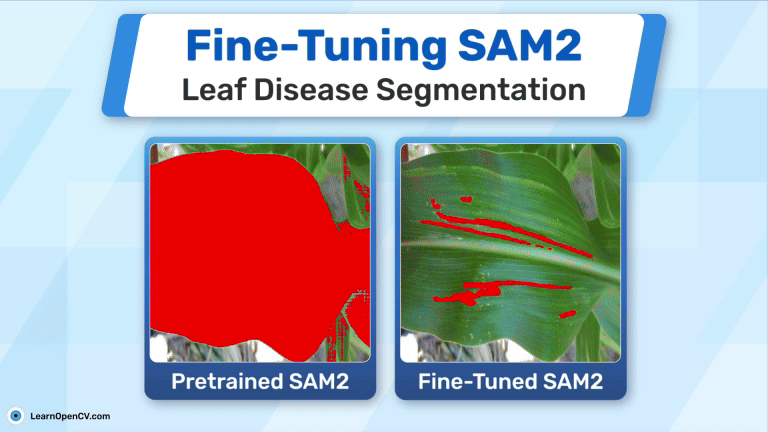
Leaf diseases reduce crop yields and impact food security. Finetuning SAM2 helps detect and segment diseased areas using deep learning. With a small dataset, we achieved 74% IoU, making early