

Models with billions, or trillions, of parameters are becoming the norm. These models can write essays, generate code, as well as create art. But they can still get stuck on a logic puzzle like Sudoku.This is where the idea of bigger is better start making less sense. This is where the concept of TRM comes into play.
In this blog post we will be exploring:
- PROBLEM with HRMs and LLMs
- TRM Architecture
- RESULTS of TRM
- ABLATION STUDY on various parameters
- A PYTHON SCRIPT on creating a custom TRM model
Let’s begin by understanding the need for TRMs.
1. The Problem with the “One-Shot” Answer
Large Language Models (LLMs) often struggle with complex puzzle-solving tasks such as Sudoku, Maze pathfinding, and Abstract Reasoning Corpus (ARC-AGI), exhibiting error propagation and costly inference. Chain-of-Thought prompting and Test-Time Compute methods can help but are computationally expensive and still prone to errors.
The Hierarchical Reasoning Model (HRM), proposed by Wang et al. (2025), attempted to address these issues using a recursive approach with two small neural networks. While HRM showed promise, it was complex and relied on heavy biological and mathematical justifications that were hard to trace back.
The TRM emerges from a critical analysis of HRM’s architecture, identifying that much of its complexity may be unnecessary. The key insight driving this research is iterative refinement. Instead of trying to get the right answer on the first try, a TRM starts with a guess and recursively improves it.
2. TRM Architecture
TRM represents a substantial simplification of recursive reasoning architectures. Instead of HRM’s two 4-layer Transformer networks, TRM uses a single 2-layer network that serves dual purposes: updating a latent reasoning feature and refining the output answer. TRMs function by trying to predict the right answer on the first try with a guess and recursively improving on it.

Imagine solving a Sudoku puzzle. We simply don’t fill out the whole grid at once. We first place a number and see how it affects the rest of the board, we might make a mistake then erase it and try again. So basically we are recursively improving our solution. TRMs do exactly this.
The three primary components of a tiny recursive model are:
Input (x): The problem or question to be solved.
Prediction (y): The current answer or solution.
Latent (z): A reasoning feature that maintains the problem context and reasoning chain.
The core recursive process follows two distinct phases:
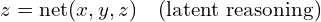
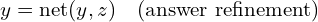
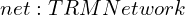
During latent reasoning, the network updates the reasoning feature by considering the original question, current answer, and existing reasoning state. During answer refinement, it focuses solely on improving the solution based on the current answer and refined reasoning.
The Recursive Loop: The model tries to improve its answer for a set number of steps (e.g., 16 times). In each of these major steps, it performs a mini-loop to “think hard.”
Train Strategy:
- Initialization: Start with the input question (
x), an initial guess for the answer (y), and an initial reasoning state (z). - Outer Loop (Improvement Steps): Repeat the following process up to
Ntimes (e.g.,N=16). - Inner Loop (Reasoning): For
ntimes (e.g.,n=6), the model focuses solely on refining its reasoning. It feeds the question (x), the current answer (y), and the current reasoning (z) back into its tiny network to produce a betterz. - Answer Update: After thinking hard for
nsteps, the model uses its newly polished reasoning (z) to make a better guess at the answer. It feeds the current answer (y) and the new reasoning (z) into the same tiny network to produce a new, bettery. - Final Output: After all the improvement steps, the final
yis the model’s solution.
This process, called deep supervision, allows the model to learn how to take any intermediate solution and make it better. It can effectively correct its own past mistakes.

3. TRM Experimental Results
The experimental validation of TRM demonstrates remarkable improvements across multiple challenging reasoning benchmarks:
Sudoku-Extreme: TRM achieved 87.4% test accuracy compared to HRM’s 55.0%, representing a 32.4 percentage point improvement with significantly fewer parameters (5M vs 27M).
Maze-Hard: The model reached 85.3% accuracy, surpassing HRM’s 74.5% while using only 7M parameters.
Abstract Reasoning Corpus (ARC-AGI): On ARC-AGI-1, TRM achieved 44.6% accuracy versus HRM’s 40.3%, and on the more challenging ARC-AGI-2, it reached 7.8% compared to HRM’s 5.0%.
Perhaps most striking is TRM’s performance relative to Large Language Models. Despite using less than 0.01% of the parameters of models like GPT-4 or Claude, TRM significantly outperforms most LLMs on these reasoning benchmarks, highlighting the importance of architectural design over raw scale for specific cognitive tasks


4. Ablation Studies on parameters used for training TRM
Comprehensive ablation studies reveal the critical importance of each design choice:
Full Backpropagation Impact: Replacing HRM’s 1-step gradient approximation with full backpropagation through recursion led to the most dramatic improvement, increasing accuracy from 56.5% to 87.4% on Sudoku-Extreme.
Network Depth Optimization: Counterintuitively, reducing from 4 layers to 2 layers improved generalization while halving parameters, suggesting that deeper networks may overfit on small training datasets typical of reasoning tasks.
Single Network Benefits: Consolidating HRM’s dual-network architecture into a single network not only reduced parameters but also improved generalization, likely due to reduced architectural complexity and better parameter sharing.
5. Python Code for training TRM network from scratch
Let’s walk through a simplified and detailed implementation of TRM using PyTorch. This will highlight the key architectural components and the training flow.
import torch
import torch.nn as nn
class TinyNetworkBlock(nn.Module):
def __init__(self, embed_dim=512, num_heads=8):
super().__init__()
self.norm1 = nn.LayerNorm(embed_dim)
self.attn = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
self.norm2 = nn.LayerNorm(embed_dim)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, embed_dim * 4),
nn.GELU(),
nn.Linear(embed_dim * 4, embed_dim),
)
def forward(self, query, context):
query = self.norm1(query)
context = self.norm1(context)
attn_output, _ = self.attn(query, context, context)
# Residual connection
query = query + attn_output
query = query + self.mlp(self.norm2(query))
return query
In the research paper, the “tiny network” is a simple block with Self-Attention and an MLP, much like a single layer of a Transformer. In the class TinyNetworkBlock, the model learns to attend to different parts of its state and the network processes the concatenated inputs x, y, z.
class TRM(nn.Module):
def __init__(self, embed_dim=512, n_reasoning_steps=6):
super().__init__()
self.net = TinyNetworkBlock(embed_dim)
self.n = n_reasoning_steps
self.input_projection = nn.Linear(embed_dim * 3, embed_dim)
self.output_head = nn.Linear(embed_dim, 10) # For Sudoku (0-9 tokens)
def forward(self, x, y, z):
for _ in range(self.n):
combined_context = torch.cat((x, y), dim=-1)
z = self.net(query=z, context=combined_context)
y = self.net(query=y, context=z)
return y, z
The above code snippet, performs one full improvement step, that is, the inner reasoning loop + answer update.
Input embeddings for the question, answer, and reasoning state are being initialized in the code snippet above by declaring them as self.input_projection and self.output_head. In a production environment, we would already have pre-defined embeddings for our vocabulary (e.g., 1-9 for Sudoku).
embed_dim = 512
batch_size = 32
max_supervision_steps = 16 # N_sup from the paper
trm_model = TRM(embed_dim, n_reasoning_steps=6)
optimizer = torch.optim.Adam(trm_model.parameters(), lr=1e-4)
loss_fn = nn.CrossEntropyLoss()
sequence_length = 81
question = torch.randn(batch_size, sequence_length, embed_dim)
true_answer_tokens = torch.randint(0, 10, (batch_size, sequence_length))
y = torch.zeros_like(question)
z = torch.zeros_like(question)
In the above code block we are constructing a custom training loop, instantiating model, creating dummy data for a sequence-based task like Sudoku(flattened grid) and initializing answer (y) and reasoning (z) states.
# The "Deep Supervision" outer loop
for step in range(max_supervision_steps):
optimizer.zero_grad()
y_embedding, z_next = trm_model(question, y, z)
predicted_logits = trm_model.output_head(y_embedding)
loss = loss_fn(predicted_logits.view(-1, 10), true_answer_tokens.view(-1))
loss.backward()
optimizer.step()
print(f"Supervision Step {step+1}, Loss: {loss.item()}")
y = y_embedding.detach()
z = z_next.detach()
Finally in the above snippet we are creating our Outer Deep Supervision Loop which performs one recursive improvement step to get new y and z embeddings. Inside this loop we are also converting the output embedding to token predictions and lastly preparing the states for next iteration by detaching them from the computational graph.

6. Conclusion
TRM represent a fundamental shift in how we might approach building intelligent systems. The key takeaway is that architectural innovation can be more powerful than brute-force scaling. While TRMs won’t replace LLMs for their core competencies like creative text generation and broad-based knowledge retrieval, they illuminate a path forward for a new class of specialized, highly efficient reasoning modules.
We can imagine future AI systems that use LLMs as a general interface but call upon compact, powerful TRM-like modules for tasks that require rigorous logic, planning, and optimization.



100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning