

Imagine being able to separate the foreground from the background in your videos with clear, accurate mattes every time. With AI models like MatAnyone, video matting delivers precise alpha mattes using consistent memory banks, ensuring smooth and reliable results across frames. This advancement opens new possibilities for video editors, filmmakers, and AI enthusiasts interested in the latest developments in video processing technology. In this post, we explore how MatAnyone works and what it means for professionals and tech-savvy creatives in the video industry.

- What is Video Matting?
- Are Video Matting and Video Object Segmentation different techniques?
- Brief overview of MatAnyone architecture
- MatAnyone dataset( VM800 ) v/s VideoMatte240k dataset
- Diving into the intricacies of various modules
- Training and Inference Strategy
- Experiments
- Key Takeaway
- Conclusion
- References
What is Video Matting?
Video Matting separates a video into distinct foreground and background layers, with alpha mattes (or transparency maps) defining how these layers blend. As shown in Fig. 1, the alpha matte is computed using the equation.


Image Source Research Gate
where 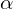 (ranges from 0 to 1) indicates the opacity,
(ranges from 0 to 1) indicates the opacity,  represents the foreground pixel value, and
represents the foreground pixel value, and 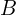 is the background pixel value.
is the background pixel value.
A notable challenge with this equation is that it can yield a trivial solution when  and
and  , regardless of . This problem forces us to introduce additional boundary conditions or auxiliary variables—often as a trimap—to resolve the ambiguity.
, regardless of . This problem forces us to introduce additional boundary conditions or auxiliary variables—often as a trimap—to resolve the ambiguity.
However, generating trimaps is both computationally expensive and resource-intensive, which has spurred the development of auxiliary-free methods. MatAnyone builds on this idea by incorporating memory banks that bypass the need for trimaps, offering a more efficient and robust solution for producing precise alpha mattes. Read on to discover how this innovative approach is reshaping video matting for filmmakers and video editors.
Are video matting and video object segmentation different techniques?
Video Object Segmentation
Video object segmentation involves assigning each pixel in a video to a specific class—typically foreground or background—to create a segmentation mask. Unlike alpha mattes, these masks contain discrete values (for example, 0 for background and 1 for foreground in binary segmentation) and usually have hard edges.
Video object segmentation models add a temporal dimension to the architecture to maintain consistency over time. However, the lack of transparency in these segmentation masks can be a drawback, mainly when processing regions with fine details like hair or smoke.
This task is widely used in object tracking, autonomous driving, and scene understanding, where precise segmentation is key to accurately interpreting video content.

Video Matting
Video matting is a process that separates a video into two distinct layers—the foreground and the background—by generating highly detailed alpha mattes. These alpha mattes offer pixel-level accuracy and capture the transparency of each pixel, where the alpha value ranges from 0 (completely transparent) to 1 (completely opaque).
Architecturally, video matting in MatAnyone employs a training strategy similar to self-supervised learning methods used in video object segmentation, using memory banks that store information from previous frames. This approach helps ensure smooth and consistent transitions across frames.
Everyday use cases include visual effects (VFX), video compositing, and augmented reality, where accurate separation of elements is crucial.
Brief Overview of MatAnyone Architecture
Human video matting methods often rely solely on the input frames, which can lead to problems when dealing with complex or ambiguous backgrounds. MatAnyone addresses this challenge by providing a robust framework built explicitly for target-assigned video matting. Depending on the architecture variant, this framework can work with auxiliary information supplied only in the first frame or throughout the video.

The image above illustrates the difference between boundary and core regions, a key factor when assigning transparency values, as pixels at the boundaries( like hair ) are much more challenging in identifying the opacity than those in the core.
MatAnyone’s architecture is composed of several innovative modules that work together to achieve precise alpha mattes:
Encoder:
A ResNet-50 pre-trained model serves as the backbone encoder. It extracts downsampled features that are transformed into key and query representations. These latent features are essential for the attention mechanisms that follow.
Consistent Memory Propagation:
Acting as the framework’s “memory system,” this module maintains consistency and accuracy across frames. At its core is the alpha memory bank, which captures historical context from previous frames and is periodically updated. An attention-driven query mechanism retrieves relevant information from this memory, ensuring stable predictions even in challenging boundary areas.

Object Transformer:
Inspired by models like Cutie and DETR, the object transformer uses a small set of object queries to iteratively refine the feature map. This helps to group pixel-level information into object-level semantics, making the segmentation more robust against distracting elements in the scene.
Decoder for Alpha Matte Decoding:
The decoder is specially modified to meet the high precision needs of video matting. Unlike standard segmentation decoders, it includes additional upsampling stages that bring the resolution back to full scale, allowing for fine details—especially around boundaries—to be accurately reconstructed.
Value Encoder:
A ResNet-18 pre-trained model is used here to refine the information stored in the memory bank. The value encoder produces refined representations that update the alpha memory bank and the memory from the last frame by processing the current frame’s predicted alpha matte and its image features. This continuous refinement is akin to improving a skill through practice.
Together, these modules enable MatAnyone to overcome traditional challenges in video matting like flickering artifacts, ambiguous backgrounds, dependence on computationally expensive inputs, etc.
MatAnyone dataset( VM800 ) v/s VideoMatte240k dataset
The MatAnyone paper introduces a novel training dataset, VM800, which significantly improves upon the limitations of the previous VideoMatte240k dataset in several key areas.
Quality of Ground-Truth Alpha Mattes:
VideoMatte240k suffers from inaccurate semantic representation in the core regions—for example, a “hole” on glasses—and a lack of fine details along object boundaries, leading to blurry edges and loss of subtle features like hair strands. In contrast, the VM800 dataset provides high-quality alpha mattes that accurately capture both the semantic core regions and fine-grained boundary details, directly enhancing the precision of the matting results.

Scale and Diversity:
VideoMatte240k is relatively tiny compared to datasets used for video object segmentation, which limits the diversity of objects and scenes available during training. VM800 is twice as large as VideoMatte240k and includes a broader range of backgrounds and object interactions. This greater diversity exposes the model to various situations, improving its robustness and applicability to real-world video matting tasks.
Realism and Generalizability:
Due to the inherent challenges of obtaining accurate human annotations for real videos, VideoMatte240k primarily consists of synthetic instances. This synthetic nature restricts the model’s ability to capture the complexities and variations present in natural videos. The VM800 dataset, on the other hand, is designed to be more realistic, effectively bridging the gap between synthetic data and real-world scenarios and thereby enhancing the generalizability of the matting models.
The paper also introduces a new test dataset, YoutubeMatte, which addresses limitations in existing test datasets.
The standard VideoMatte test set, derived from VideoMatte240k, includes only five unique foreground videos, severely limiting the evaluation of models across diverse scenarios. YoutubeMatte comprises 32 distinct green-screen foreground videos at a resolution of 1920×1080, sourced from YouTube.
While VideoMatte240k contains a mix of 4K and HD videos, its evaluation split is heavily imbalanced with only five videos, reducing its effectiveness for robust testing. YoutubeMatte’s consistent high-definition resolution helps the MatAnyone model handle detailed textures and delicate structures better, resulting in more realistic and reliable matting outcomes.

Data Generation Pipeline Overview
MatAnyone introduces a robust data generation pipeline designed to create high-quality datasets for video matting.
While you can skip this section to focus on the architecture, understanding the pipeline provides valuable context on how the dataset overcomes previous limitations. Here’s an overview of their approach:
- Collection Sources:
- Green screen videos are sourced from three major stock footage websites—Storyblocks, Envato Elements, and Motion Array. This ensures the dataset features various people, clothing styles, hairstyles, and actions, supporting realistic and diverse video matting scenarios.
- Automated Alpha Matte Extraction:
- Adobe After Effects is used in an automated pipeline to efficiently handle large footage volumes. Key steps include:
- Keylight Effect: Removes the green screen background by setting the ‘Screen Color’ from the upper-left corner of each frame and fine-tunes the matte with ‘Clip Black’ set to 20 and ‘Clip White’ set to 80.
- Key Cleaner Effect: Refines the matte edges with a radius of 1 and enables the ‘Reduce Chatter’ option to minimize flickering along boundaries.
- Advanced Spill Suppressor: Eliminates residual green spill in the foreground, ensuring accurate color representation.
- Adobe After Effects is used in an automated pipeline to efficiently handle large footage volumes. Key steps include:
This process is automated using a combination of JavaScript and XML files, enabling batch processing of the footage to generate preliminary alpha mattes.
- Manual Quality Assurance:
- After the automated processing, the alpha mattes undergo a thorough manual review to fix common artifacts such as:
- Reflective Surfaces: Correcting issues like holes in glasses caused by reflections.
- Inhomogeneous Alpha Values: Addressing inconsistencies in core regions due to shadows or colors similar to the green screen.
- After the automated processing, the alpha mattes undergo a thorough manual review to fix common artifacts such as:
This pipeline combines efficient automated processing with rigorous manual quality checks, resulting in a diverse, high-quality dataset that significantly advances video matting research.
Diving into the intricacies of various modules
In this section, we will explore advanced aspects of the MatAnyone model’s architecture by delving into four key components: the Memory Bank module, the CMP module, the Object Transformer, and the modified DDC loss function.
To start, we will first clarify the concept of the memory bank.
Understanding AI memory banks
Memory networks refer to neural networks with external memory where information can be written and read anytime. A good analogy to visualize the implementation and importance of memory banks is to compare these modules with an organized digital storage unit, which AI models consult whenever they need to remember past events or data.
Terminologies
Query Frame—> Current Frame
Memory Frame—> Past frame with object masks
Long-term memory—> Stores compact representations of features from earlier frames, enabling the model to recall and utilize information from the distant past.
Sensory memory—> Rapidly captures immediate visual features from the current frame, providing a quick snapshot of the scene.
Memory Reading
During this operation, the model accesses stored information from its memory bank. The memory bank serves as a reference, drawing on previous frames and object features to enrich the current prediction.

A feature that represents combined information from both long-term and working memory is computed via a readout operation given by:

Here,  is an affinity matrix computed by applying a softmax on the memory dimension of the similarity matrix
is an affinity matrix computed by applying a softmax on the memory dimension of the similarity matrix  . The similarity matrix is defined as:
. The similarity matrix is defined as:
![S(k, q) = - s(i,j) \sum_{c=1}^{C_k} e(c,j) \left[ k(c,i) - q(c,j) \right]^2](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-58a0abc2bc3f9f0927f8742aed93b5fb_l3.png)
In this context:
 and
and  are the keys and values for
are the keys and values for  memory elements stored in both long-term and working memory.
memory elements stored in both long-term and working memory.- The query
 is obtained from the query frame via the query encoder.
is obtained from the query frame via the query encoder. - has a size of
 and maps each query element to a distribution over all memory elements, thereby aggregating the corresponding values
and maps each query element to a distribution over all memory elements, thereby aggregating the corresponding values  .
.
Note: If  for all
for all  ,
,  , and
, and  , this similarity function reduces to a standard
, this similarity function reduces to a standard  distance.
distance.
Affinity Matrix:
The affinity matrix is derived by applying a softmax across the memory dimension (rows) of the similarity matrix , which captures pairwise similarities between every key and query element.
Similarity Function:
This function is an anisotropic function that includes two scaling terms:
- The shrinkage term
 is associated with the query, where
is associated with the query, where ![e \in [0, 1]^{C_k \times HW}](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-27caae1f84e71b1e22cd6235e8a7cb4a_l3.png) .
. - The selection term
 is associated with the key, where
is associated with the key, where  .
.
The above terms help break the symmetry between key and query, allowing the similarity measure to adapt more flexibly than a standard L2 norm.
This refined readout operation and the associated affinity computation enable the model to leverage past information stored in the memory bank, ensuring that relevant object features are appropriately integrated into the current frame’s prediction.
Long-term Memory
Long-term memory significantly enhances a system’s ability to analyze complex tasks over extended periods, especially in video matting and video object segmentation.
The Xmem paper proposes a memory consolidation procedure that selects representative keys, called prototypes, from the working memory and enriches them using a memory potentiation algorithm.
When the working memory—serving as a high-resolution temporary buffer—reaches its predefined capacity ( denoted by  ), the model initiates a memory consolidation process. This process prioritizes frequently accessed or critical information by keeping essential frames (such as the initial annotated frame and the most recent frames, denoted by
), the model initiates a memory consolidation process. This process prioritizes frequently accessed or critical information by keeping essential frames (such as the initial annotated frame and the most recent frames, denoted by  ) in working memory while transferring less immediately relevant frames (referred to as candidate frames) into long-term memory.
) in working memory while transferring less immediately relevant frames (referred to as candidate frames) into long-term memory.

Image Source
The three key terms introduced here—Prototypes, Potentiation, and Consolidation—are explained in detail below.
Prototype Selection:
Only a small, representative subset from the candidate frames is chosen based on their keys’ relevance and usage frequency. These selected keys are termed “prototypes.” The reasoning behind choosing only a subset is that the size of the resultant long-term memory grows with the number of prototypes, so an optimal number must be determined.
The usage of each candidate is calculated as follows:

This metric helps identify which candidate keys are most valuable for long-term storage.
Memory Potentiation:
Initially, the prototype keys selected from the candidate frames might be sparse or discrete, which could lead to information loss if values were sampled directly. A filtering and aggregation process called memory potentiation is applied to prevent this. Operating in a high-dimensional key space, it uses the relationships between keys to reduce blurriness around object boundaries.
In this process, each prototype key aggregates values from all candidate keys through a weighted average. The weights are derived from a softmax function applied to the similarity function, calculated between candidate and prototype keys.
Mathematically, the prototype values are computed as follows:

Here,  represents the affinity matrix obtained by applying a softmax function to the similarity matrix
represents the affinity matrix obtained by applying a softmax function to the similarity matrix  , effectively mapping each prototype to a distribution over the candidate keys. This refined aggregation process produces more prosperous and representative memory prototypes, significantly improving memory recall and accuracy.
, effectively mapping each prototype to a distribution over the candidate keys. This refined aggregation process produces more prosperous and representative memory prototypes, significantly improving memory recall and accuracy.
Memory Consolidation:
When the working memory reaches its capacity limit, the memory consolidation process comes into play. It transfers the less critical candidate frames into long-term memory while retaining the most essential frames in the working memory. This process helps manage the overall memory size and ensures that the system always has access to the most important and frequently used information.
Working or Short-term memory
The working memory acts as a temporary high-resolution buffer. It serves as a gateway to long-term memory by estimating the importance of each memory element based on its usage frequency.
It comprises two main components: keys and values. The key is encoded solely from the image and shares the same embedding space as the query, while the value is encoded from both the image and the corresponding mask.

At every  frame, the following steps occur:
frame, the following steps occur:
- Copy the Query as a New Key: The current query is copied to form a new key.
- Generate a New Value: The image and the predicted mask are processed through the value encoder to produce a new value.
- Update Working Memory: The new key-value pair is appended to the working memory, making it available for future memory reading operations.
Sensory Memory
Sensory memory focuses on the short term and retains low-level information such as object locations and movements. Due to the broader temporal scope of working and long-term memories, sensory memory provides essential content over a very short time interval.
Sensory memory utilizes a hidden representation,  , which is initialized with zeros and dynamically updated by a Gated Recurrent Unit (GRU).
, which is initialized with zeros and dynamically updated by a Gated Recurrent Unit (GRU).

Regular, incremental updates update Sensory memory with multi-scale decoder features at every frame.
At specific intervals (every frame), sensory memory undergoes a “deep” update—where extra, detailed features extracted from the value encoder are incorporated via another GRU. This strategy ensures that sensory memory remains relevant and concise by discarding redundant information already in the working memory while benefiting from rich feature updates with minimal computational overhead.


Understanding Object Query Transformers or Cutie (qt)
The most significant breakthrough brought by object transformers is their ability to model objects as distinct features rather than relying solely on pixel-level representations.
Traditional vision transformers process pixels uniformly, but object transformers use learned object queries and attention mechanisms to explicitly reason about individual objects and their spatial relationships. This capability allows them to capture high-level semantic information and distinguish foreground objects from background clutter.
As a result, tasks like video matting, video object segmentation, and object detection saw improved performance.
Object Queries
Definition:
Object queries are tensors of learned embedding vectors. Each query vector is trained to focus on a specific object, acting as a placeholder for that object’s features. The object queries have a fixed shape of  , where:
, where:
- is the number of object queries (typically a fixed number like 100, regardless of the number of objects in the image).
 is the channel size.
is the channel size.
Key Characteristics:
- Learned Embeddings:
The object queries are randomly initialized and refined during training. - Distinct Object Representation:
They allow the network to represent each object separately, summarizing its characteristics. - Independence from Object Count:
A fixed number of queries is used, making the system robust to varying numbers of objects.
Pipeline Overview
Inputs:
- Pixel-Level Features:
Obtained from a query encoder (typically a CNN backbone). - Object-Level Features:
Extracted from a mask encoder that converts ground truth segmentation masks from previous frames into concise embeddings. - Object Queries:
Learnable embedding vectors that are iteratively refined by the transformer decoder to specialize in detecting distinct objects or background regions.
Flow:
- Initial Fusion:
Before performing masked cross-attention, static object queries are added to dynamic object memory. - Masked Cross Attention:
Object queries attend to pixel-level features, where the attention mechanism splits queries such that one half focuses on the foreground and the other on the background. - Self-Attention and Feed-Forward Layers:
The queries are refined through standard self-attention and feed-forward layers, which help model object-level reasoning. - Reverse Cross Attention:
In a subsequent step, object queries return their object-level semantics to update the pixel features. - Final Processing:
The updated pixel features pass through a feed-forward network before moving on to the decoder for the final task.

Understanding Consistent Memory Propagation( CMP )
Understanding the Consistent Memory Propagation (CMP) module—unique to MatAnyone—reveals how the model maintains stability and precision in video matting, especially along complex boundaries. Traditional memory-based methods store segmentation masks or trimaps, but they often struggle with flickering and inconsistent boundaries. MatAnyone tackles these issues by storing full alpha mattes in an alpha memory bank, thereby preserving fine details, particularly in boundary regions.

Region-Adaptive Memory Fusion
After exploring the differences between segmentation maps (values of 0 or 1) and matting maps (values between 0 and 1), it becomes clear that the memory-matching approach must account for these differences.
Traditional methods assume all query tokens are equally important when matching memory values. However, a query frame can be divided into core regions (which show little change between frames) and boundary regions (which exhibit significant changes in alpha values). Most significant changes occur in the boundary regions, while the core regions remain relatively stable.
MatAnyone addresses this by introducing a boundary-area prediction module. This module estimates a change probability  for each pixel in the current frame. Higher values of
for each pixel in the current frame. Higher values of  indicate that a pixel is likely in a boundary region (significant changes in alpha). In comparison, lower values indicate it is in a stable core region (minor changes).
indicate that a pixel is likely in a boundary region (significant changes in alpha). In comparison, lower values indicate it is in a stable core region (minor changes).
A sigmoid function is applied to  to convert it into a probability. Based on these probabilities during region-adaptive memory fusion, the network performs a soft merge between the current memory bank values and the previous frame’s values.
to convert it into a probability. Based on these probabilities during region-adaptive memory fusion, the network performs a soft merge between the current memory bank values and the previous frame’s values.
The following equation expresses soft merge:

Where:
 are the values propagated from the previous frame, and
are the values propagated from the previous frame, and- is the change probability for each pixel.
 are the current values queried from the memory bank.
are the current values queried from the memory bank.
This approach ensures that information from stable regions (core) is preserved. At the same time, the model adapts more aggressively in regions where significant changes occur (boundaries), thus maintaining high-quality, temporally consistent alpha mattes.

Understanding Loss Functions Used by MatAnyone Model
- Matting Loss
This loss penalizes differences in the predicted and actual alpha mattes on a pixel-wise basis and emphasizes preserving the subtle transitions along object boundaries. Additionally, it enforces consistency in the predictions over time, which is critical for video applications where flickering can be detrimental.- L1 loss( Semantic Accuracy )
- Equation:

- Explanation:
 is the predicted alpha matte for frame t, and
is the predicted alpha matte for frame t, and  is its corresponding ground truth.
is its corresponding ground truth.- The L1 loss calculates the sum of absolute differences across all pixels, directly penalizing deviations between the prediction and the ground truth.
- This loss drives the overall semantic correctness by ensuring that the average predicted alpha values align closely with the actual values.
- Equation:
- Pyramid Laplacian Loss( Fine Details )
- Equation:

- Explanation:
 denotes the laplacian pyramid representation at scale
denotes the laplacian pyramid representation at scale  of the alpha matte.
of the alpha matte.- By decomposing the image into multiple scales, this loss captures discrepancies in coarse and fine details, which is especially important along object boundaries.
- The scaling factor
 appropriately weights contributions from each level, ensuring that finer details receive adequate emphasis during training.
appropriately weights contributions from each level, ensuring that finer details receive adequate emphasis during training.
- Equation:
- Temporal Coherence Loss
- Equation:

- Explanation:
- This loss measures the difference between the temporal derivatives of the predicted alpha matte and the ground truth .
- It enforces that the rate of change in the predicted matte follows that of the ground truth, thus reducing abrupt transitions between consecutive frames.
- The L2 norm penalizes more significant discrepancies more heavily, promoting smoother transitions and minimizing flickering over time.
- This loss measures the difference between the temporal derivatives of the predicted alpha matte
- Equation:
- Combined Matting Loss
- Equation:

- Explanation:
- The overall matting loss is a weighted sum of the L1 loss, the pyramid Laplacian loss (weighted by a factor of 5 to emphasize boundary details), and the temporal coherence loss.
- This combination ensures a balanced approach, where the network learns to produce alpha mattes that are semantically accurate, rich in fine details, and temporally consistent.
- Equation:
- L1 loss( Semantic Accuracy )
- Segmentation Loss
Segmentation loss helps enforce robust semantic segmentation by directly penalizing pixel-wise classification errors. This supervision is crucial for maintaining the overall structure of the object, particularly in the core regions where the foreground and background are clearly defined. The network benefits from local accuracy and global overlap measures by combining cross-entropy and Dice losses.- Cross-Entropy Loss
- Equation:

- Explanation:
 is the predicted segmentation mask for frame
is the predicted segmentation mask for frame  , and
, and  is the ground truth mask.
is the ground truth mask. - The cross-entropy loss is computed per-pixel basis, penalizing misclassifications by comparing the predicted probabilities against the actual labels.
- This loss drives the network to accurately differentiate between the foreground and background.
- Equation:
- Dice Loss
- Equation:

- Explanation:
- Dice loss measures the overlap between the predicted and ground truth masks, which is crucial for cases where the foreground occupies a small portion of the image.
- The smoothing factors (the additional 1’s) help stabilize the computation by avoiding division by zero.
- It directly optimizes for the global overlap, complementing the pixel-wise focus of the cross-entropy loss.
- Equation:
- Combined Segmentation Loss:
- Equation:

- Explanation:
- By combining cross-entropy and Dice losses, the segmentation loss leverages detailed pixel-wise accuracy and overall region similarity.
- This robust supervisory signal helps improve the semantic segmentation quality, supporting the matting task.
- Equation:
- Cross-Entropy Loss
- Core Supervision Loss
This loss focuses on ensuring that the central parts of the object (which ideally should have binary alpha values) are predicted accurately while also sharpening the transitions at the boundaries. By targeting these specific areas, the core supervision loss enhances the semantic accuracy and the fine detail of the alpha mattes.- Core Region Loss
- Conceptual Explanation:
- In the core regions of an object, the alpha values should ideally be binary (either 0 or 1).
- Although the exact formulation for the core region loss is not specified, it is typically implemented as a pixel-wise loss (such as L1) applied selectively to these regions.
- Purpose: This loss reinforces that the inner regions of the object are accurately segmented, ensuring a stable and unambiguous representation.
- Conceptual Explanation:
- Boundary Loss( scaled Directional Distance Consistency or scaled DDC )
- Equation:

- Explanation:
- Here,
 and
and  are the predicted alpha values at pixels and , while
are the predicted alpha values at pixels and , while  represents the L2 norm of the difference between their color intensities.
represents the L2 norm of the difference between their color intensities.  approximates the difference between the foreground and background colors within a local window, computed as averages from the top
approximates the difference between the foreground and background colors within a local window, computed as averages from the top  highest and lowest pixel values, respectively.
highest and lowest pixel values, respectively. - The set
 selects neighboring pixels with the most considerable intensity differences, which are key to capturing detailed transitions at the boundaries.
selects neighboring pixels with the most considerable intensity differences, which are key to capturing detailed transitions at the boundaries. - Purpose: This scaled Differential Detail Consistency (DDC) loss ensures that subtle transitions at object boundaries are preserved, promoting smooth and natural changes in the alpha matte.
- Here,
- Equation:
- Combined Core Supervision Loss:
- Equation:

- Explanation:
- The combined core supervision loss LcsL_{cs}Lcs is the sum of the core region loss and the boundary loss, with the boundary loss weighted by 1.5 to emphasize fine boundary details.
- Purpose: This combined loss ensures the network receives intense supervision for clearly defined core regions and the delicate transition zones along object edges.
- Equation:
- Core Region Loss
In conclusion
1) Matting Loss: Balances semantic accuracy (L1 loss), fine detail preservation (pyramid Laplacian loss), and temporal consistency (temporal coherence loss) to produce high-quality alpha mattes.
2)Segmentation Loss: Combines cross-entropy and Dice losses to enforce robust pixel-wise classification and overall region similarity, enhancing semantic segmentation.
3)Core Supervision Loss: Focuses on accurately segmenting the object’s core and refining its boundaries, ensuring that binary regions and subtle transitions are captured effectively.
Training and inference strategy

Training Strategy
Stage 1: Initialization with Video Matting Data
The training begins with short video sequences (typically three frames per second) to help the model learn basic memory propagation and temporal information handling.
Once the network performs well on these short sequences, the length is extended to 8 frames. This gradual increase, along with adjusted sampling intervals, allows the network to handle more complex temporal dynamics and scenarios where object appearance may change significantly.
Additionally, following established practices, video and image segmentation data are used to train the segmentation head in parallel with the matting head.
Stage 2: Core Supervision with Segmentation Data
In this stage, extra supervision is provided to the matting head using segmentation data. This additional guidance enhances the network’s semantic robustness and helps improve generalizability in real-world applications. Training is carried out with a reduced learning rate over a sequence length of 8 frames for 40,000 iterations, utilizing both matting and segmentation datasets to reinforce consistency in the object’s core regions.
Stage 3: Fine-tuning with high-quality image matting data
The final stage involves fine-tuning the model using high-quality image matting datasets such as D646 and AIM. This step focuses on enhancing the fine-grained details along object boundaries. Fine-tuning is performed with an even lower learning rate and over a shorter number of iterations, enabling the model to make incremental improvements in its predictions and further refine boundary precision.
Key elements of the training process:
Dynamic Memory Update: The model continuously updates its memory throughout the training. The outputs from previous frames (initially provided as ground truth and later as estimated masks) are fed back into the memory. This dynamic update mechanism allows the model to adapt to changes in object appearance over time without the need for online re-training.
Data Diversity and Augmentation: The training process incorporates various video sequences and images. Augmentation strategies simulate realistic changes in appearance, scale, and motion, ensuring that the model is exposed to diverse scenarios and is robust to real-world variations.

Inference Strategy
Recurrent Refinement:
A key challenge in video matting is that the first frame’s prediction quality extensively influences the subsequent frames. To address this, MatAnyone employs a recurrent refinement strategy during inference. This involves repeating the first frame multiple times—using the provided first-frame segmentation mask—to iteratively refine its alpha matte. The final prediction from this iterative process is then used to initialize the memory bank. This “warm-up” approach ensures the memory bank starts with a high-quality matte, leading to more consistent and accurate predictions in later frames.
Auxiliary-Free Variant:
In cases where an initial segmentation mask is unavailable, the model can operate in an auxiliary-free mode. In this variant, the first-frame alpha matte is generated using an external auxiliary-free method and then binarized to create a pseudo mask that initializes the memory. This flexibility makes the approach adaptable and allows for direct comparisons with other auxiliary-free methods, ensuring that the advantages of the memory-based framework are maintained even when the initial guidance is less precise.
Experiments
In this section, we examine the inference results produced by the MatAnyone model on the Kaggle platform, utilizing a P100 GPU to meet memory requirements.
We also walk through the code implementation step-by-step.
First, create a virtual environment to ensure all dependencies are appropriately managed before cloning the repository.

conda create -n matanyone python=3.13 -y
conda activate matanyone
!git clone https://github.com/pq-yang/MatAnyone
%cd MatAnyone
!pip install -e .
!pip3 install -r hugging_face/requirements.txt
Clipping, Masking, and Inferencing
For visualization, we will provide the output of each step after each code block. So, let’s start with the video given below. The total length of this video is 60 seconds. Hence, it needs to be clipped.
As MatAnyone can cause OOM( Out Of Memory ) errors for longer videos, it is best to clip down the video to 7 or 8 seconds in length. You can use the following code to clip a video using OpenCV:
current_frame = 0
while cap.isOpened():
print("working...")
ret, frame = cap.read()
if not ret:
break
if start_frame <= current_frame <= end_frame:
out.write(frame)
current_frame += 1
# print(current_frame)
if current_frame > end_frame:
break
MatAnyone, as explained in the sections above, requires the segmentation mask for the target object extracted from the initial or first frame.
This step can be completed in two steps:
- Extracting the first frame.
- Creating the binary mask of the required object using SAM2( model suggested by the authors ).
vidcap = cv2.VideoCapture('input_path')
ret ,image = vidcap.read()
cv2.imwrite("output_name", image)
success,image = vidcap.read()
print('First Frame Extraction: ', success)

Note: Before importing Ultralytics directly, pip-install Ultralytics in your local virtual environment.
from ultralytics import SAM
model = SAM("sam2.1_b.pt") #you can use any other checkpoint as well.
results = model(img, project = "save_dir_path", save = True)
# if the predicted mask doesn't match your desired mask or contains discrepancies you can use the `points` argument in the model instance and pass the keypoint location( in pixel coordinates ) to make the model predictions precise and remove the unnecessary masks created on the way.

Finally, binary masks will be created based on the results obtained. Remember to save the mask of the foreground object, nothing else.

Performing inference with MatAnyone is a one-line code step
!python inference_matanyone.py -i /path/to/input/video.mp4 -m /path/to/intial/binary/mask --max_size=1080
Passing the --max_size argument means that the resolution of the input video frames will be reduced to the value passed to the --max_size.
We have created a small dataset with masks for initial frames, which are also included in the dataset, over the Kaggle platform. It contains 11 video files, with which you can perform inferencing with MatAnyone. The link to the dataset is provided in the references section.
Key Takeaway
Consistent Memory Propagation: MatAnyone uses an advanced memory bank to maintain temporal stability and produce high-quality alpha mattes across video frames.
Region-Adaptive Fusion: By treating core and boundary regions differently, the model preserves fine details—such as hair and soft edges—ensuring realistic transparency.
Robust Training Pipeline: A multi-stage training strategy, including dynamic memory updates and data augmentation, equips the model to handle diverse and challenging video scenarios.
Enhanced Dataset Quality: The new VM800 dataset provides higher-quality, more diverse alpha mattes than previous datasets, significantly improving matting performance.
Flexible Inference Modes: The model supports auxiliary-guided and auxiliary-free configurations, making it adaptable for various applications like VFX, video compositing, and augmented reality.
Conclusion
MatAnyone offers a fresh take on video matting by leveraging past information to produce clear and stable alpha mattes. Its focus on core regions and fine boundary details makes it a promising solution for practical video editing. This method improves visual consistency and allows faster and more reliable video matting in real-world applications. Enjoy exploring the potential of MatAnyone and how it can enhance your video projects!
References
MatAnyone Research Paper: https://arxiv.org/pdf/2501.14677
MatAnyone Github repo: https://github.com/pq-yang/MatAnyone/tree/f68518023026e70a169e862acf8e885fac6f0c71
The earliest Implementation of Space-time Memory modules for video object segmentation was presented in the research paper provided here: https://arxiv.org/pdf/1904.00607v2
Query Object Transformer research paper: https://arxiv.org/pdf/2310.12982
Dataset: https://www.kaggle.com/datasets/bhomiksharma/mat-anyone/data





100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning