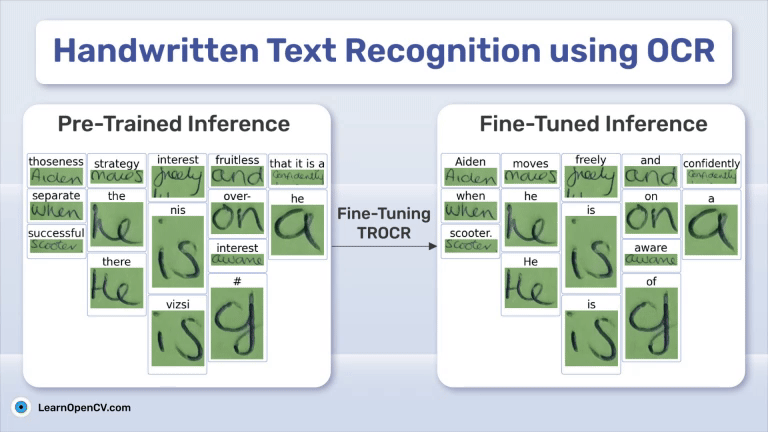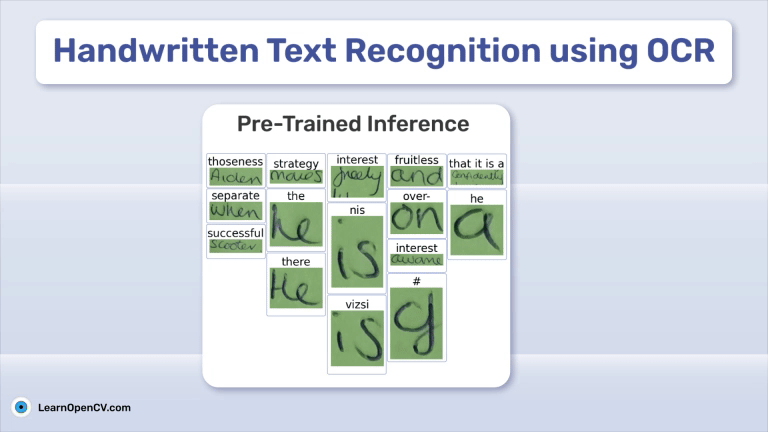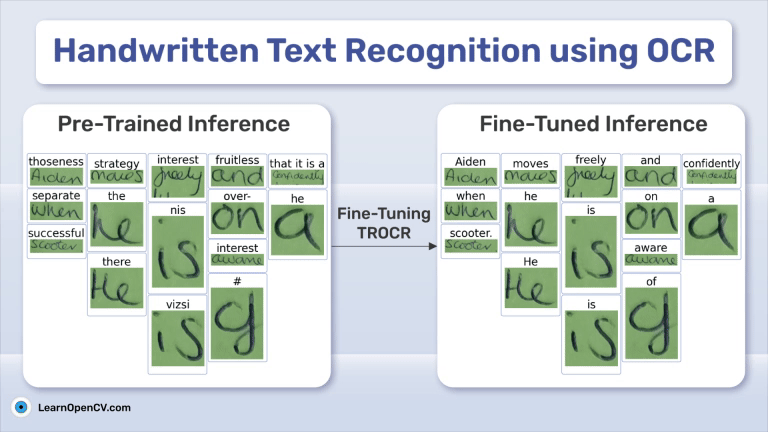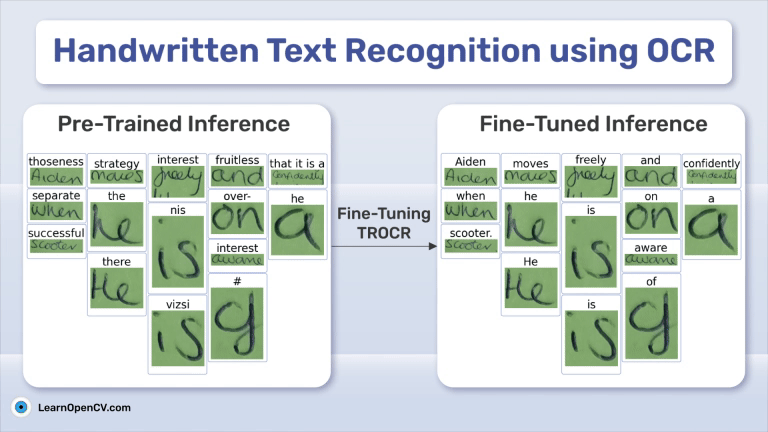
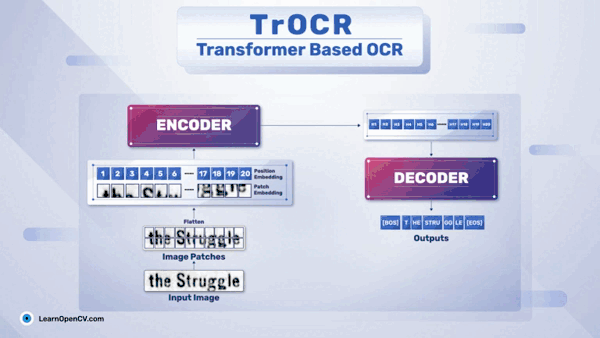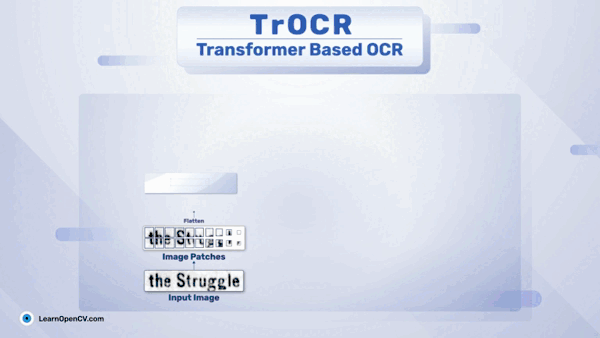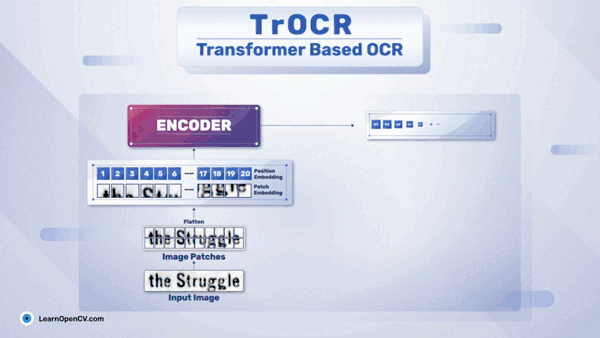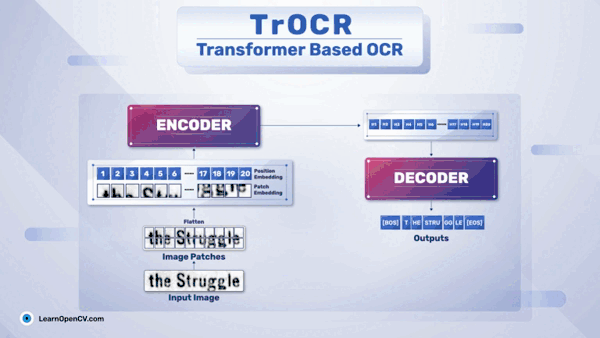
DeepSeek OCR Paper Explanation and Test using Transformers and vLLM Pipeline. Understanding Context Optical Compression and model architecture in depth.
Traditional Optical Character Recognition (OCR) systems are primarily designed to extract plain text from scanned documents or images. While useful, such systems often ignore semantic structure, layout, and visual cues
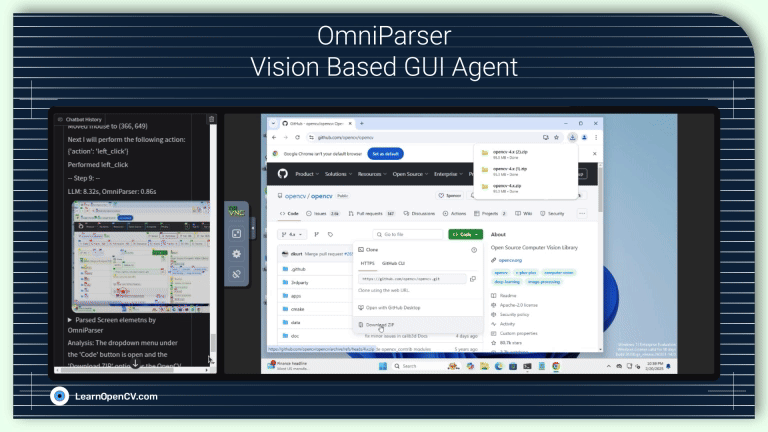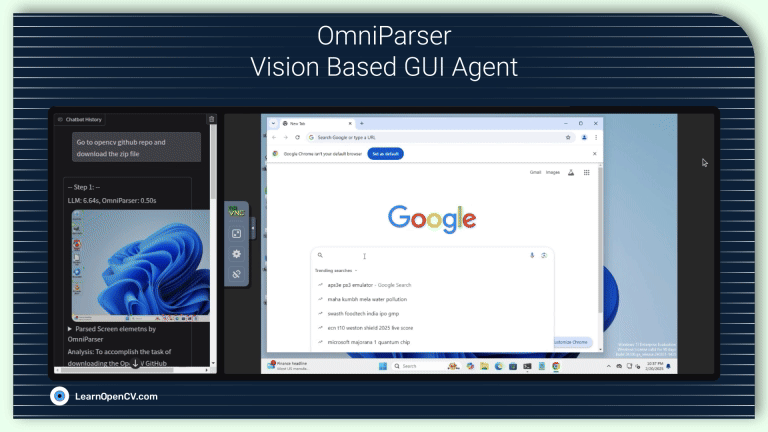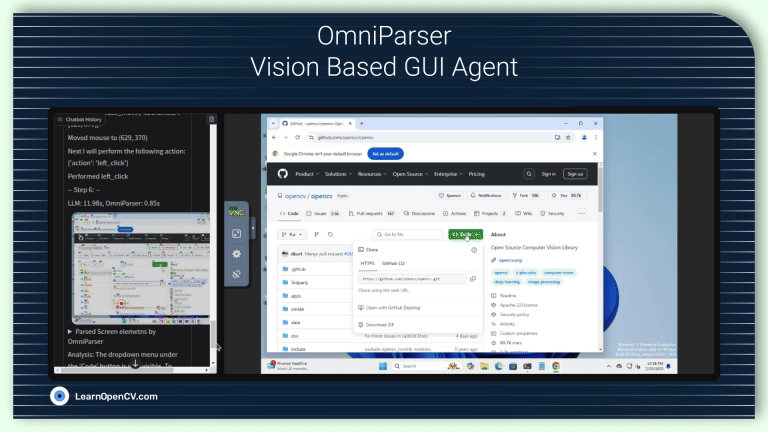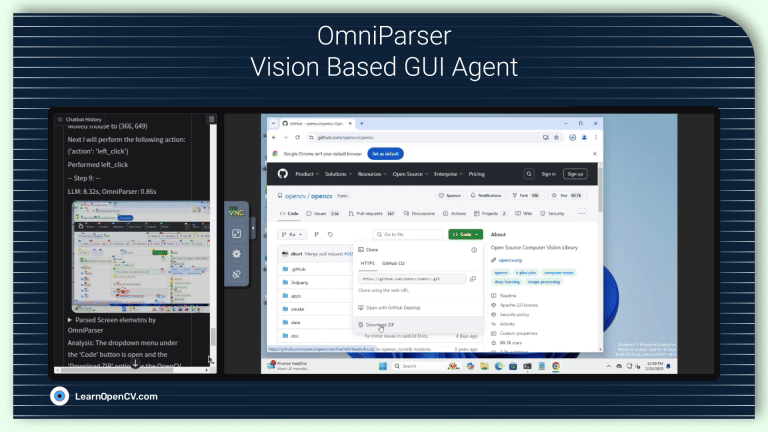
In this article, we explore OmniParser a UI screen parsing pipeline combining fine-tuned YOLO model for icon detection and Florence2 for icon recognition and icon description generation.
Optical Character Recognition is the process of recognizing text from an image by understanding and analyzing its underlying patterns. We will implement and compare various OCR algorithms provided by PaddleOCR
Deep learning has been one of the fastest-growing technologies in the modern world. Deep learning has become part of our everyday life, from voice-assistant to self-driving cars, it is everywhere.
In this article, we will learn deep learning based OCR and how to recognize text in images using an open-source tool called Tesseract and OpenCV. The method of extracting text