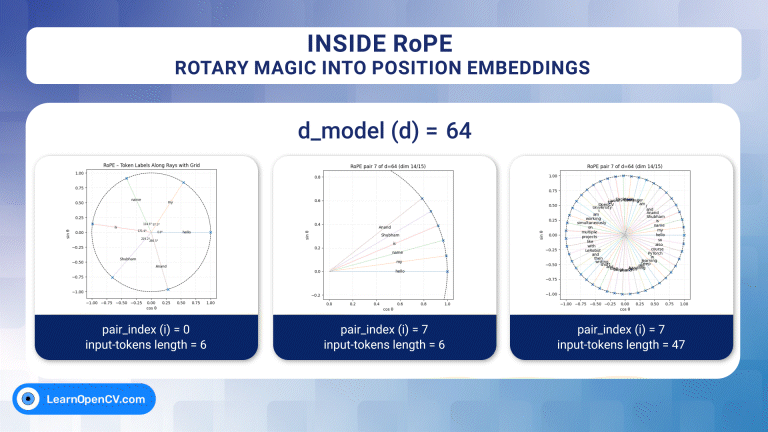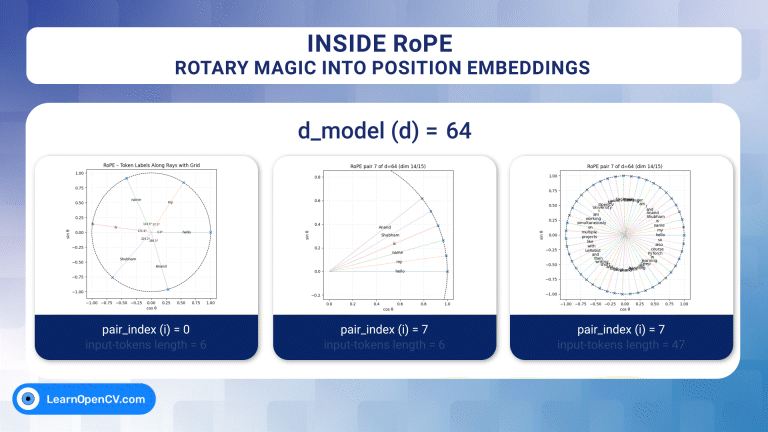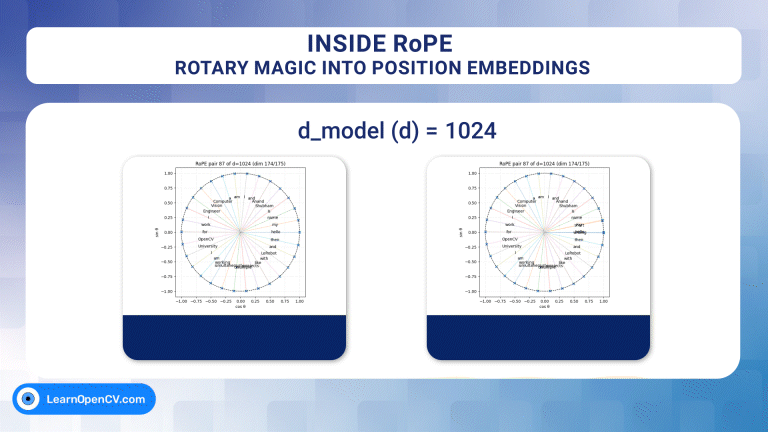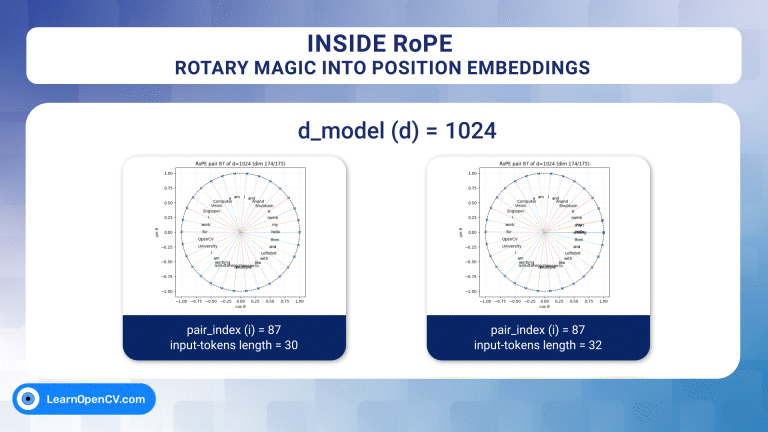
For over a decade, progress in deep learning has been framed as a story of better architectures. Yet beneath this architectural narrative lies a deeper and often overlooked question –
SAM 3D is Meta’s groundbreaking foundation model for reconstructing full 3D shape, texture, and object layout from a single natural image. Learn how it works.
Discover Image-GS, an image representation framework based on adaptive 2D Gaussians, outperforming neural and classical codecs in terms of real-time efficiency.
Discover VideoRAG, a framework that fuses graph-based reasoning and multi-modal retrieval to enhance LLMs' ability to understand multi-hour videos efficiently.
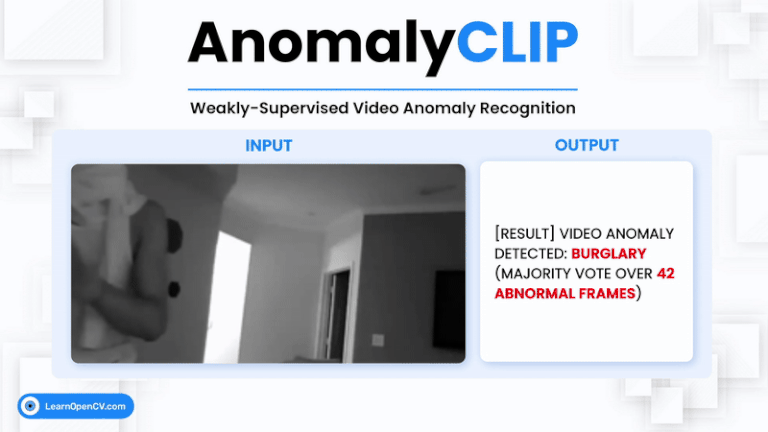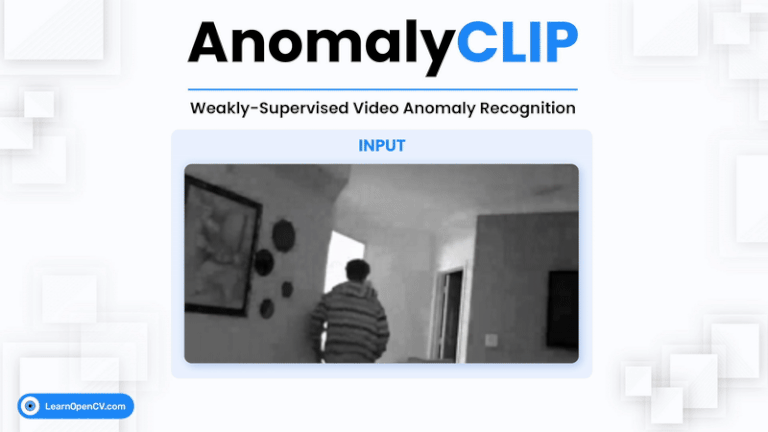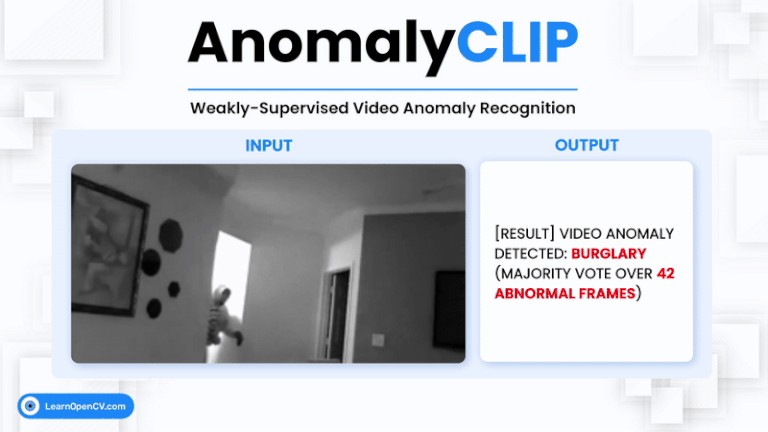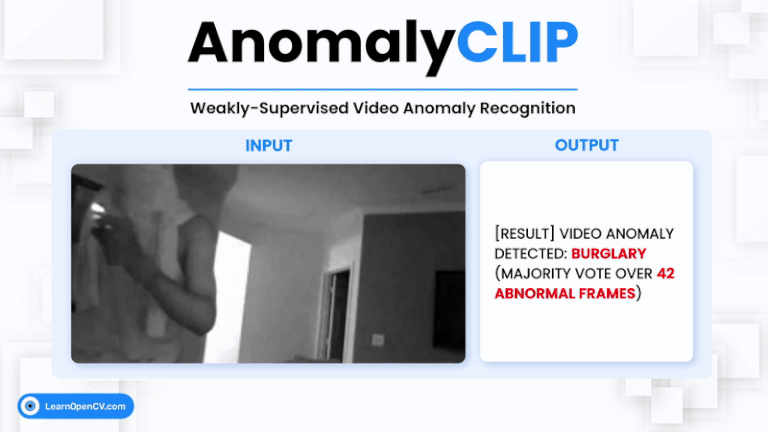
Video Anomaly Detection (VAD) is one of the most challenging problems in computer vision. It involves identifying rare, abnormal events in videos – such as burglary, fighting, or accidents –
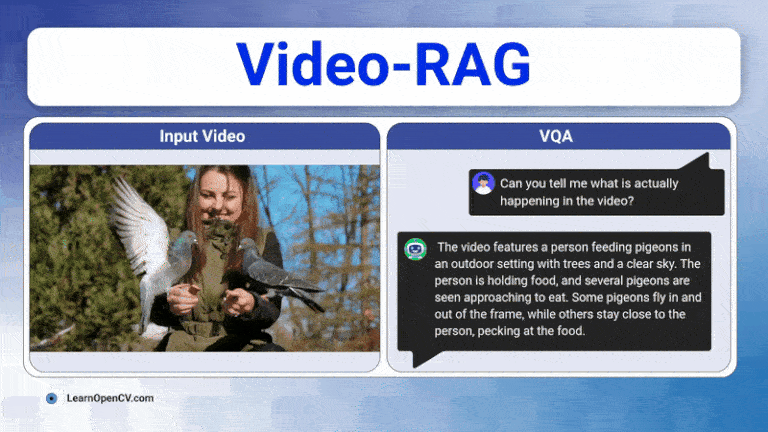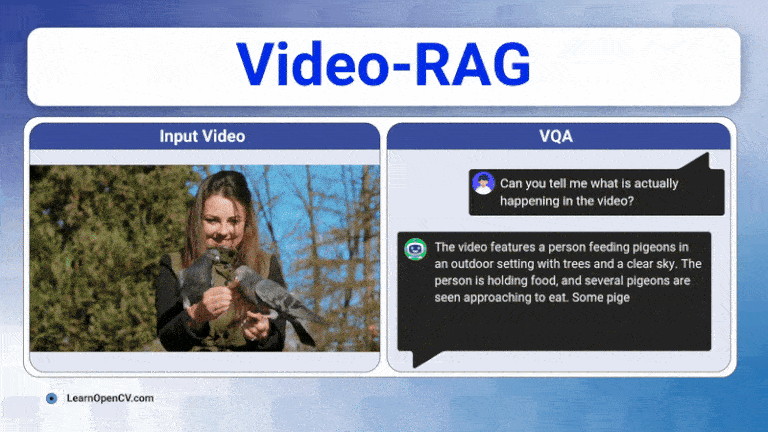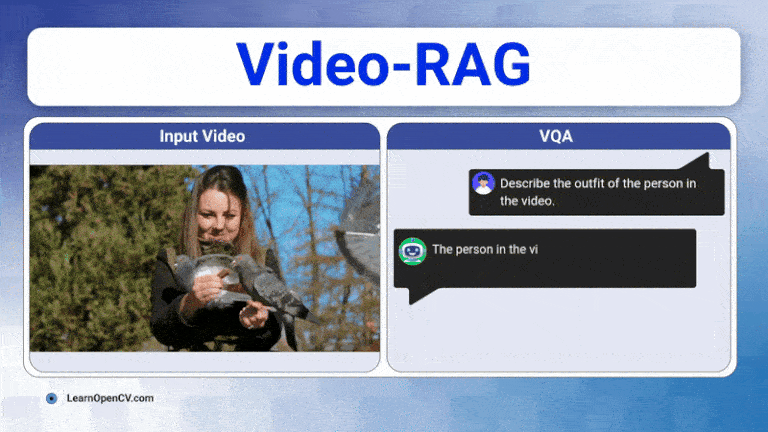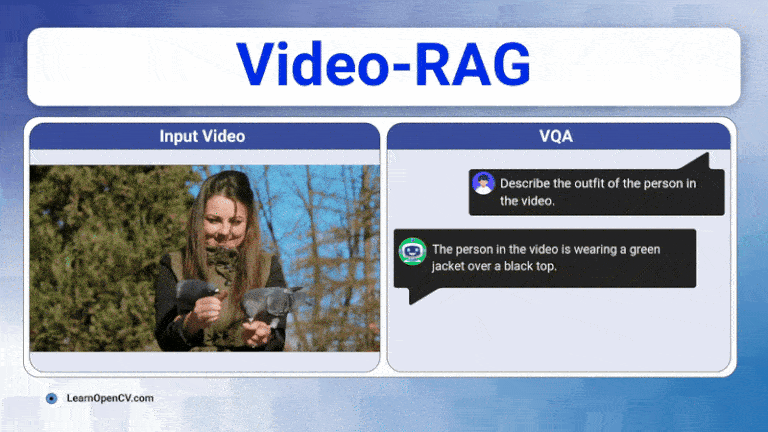
Learn how Video-RAG boosts training-free and low-compute long-video understanding by pairing OCR, ASR, and open-vocabulary detection with any long-video LVLMs.
In the groundbreaking 2017 paper “Attention Is All You Need”, Vaswani et al. introduced Sinusoidal Position Embeddings to help Transformers encode positional information, without recurrence or convolution. This elegant, non-learned
Self-attention, the beating heart of Transformer architectures, treats its input as an unordered set. That mathematical elegance is also a curse: without extra signals, the model has no idea which
In the evolving landscape of open-source language models, SmolLM3 emerges as a breakthrough: a 3 billion-parameter, decoder-only transformer that rivals larger 4 billion-parameter peers on many benchmarks, while natively supporting
Zero-shot anomaly detection (ZSAD) is a vital problem in computer vision, particularly in real-world scenarios where labeled anomalies are scarce or unavailable. Traditional vision-language models (VLMs) like CLIP fall short