
For the past decade, the AI industry has been obsessed with “Structural Depth” – the idea that to make a model smarter, we simply need to stack more layers. However, even our most advanced Large Language Models (LLMs) like GPT-4 and Llama-3 suffer from a fundamental flaw: they are static. Once the training phase ends, their weights are frozen. They “read” a prompt, but they don’t truly “learn” from it in real-time. The HOPE (Hierarchical Optimizing Processing Ensemble) architecture is now designed to shatter that barrier. By moving beyond fixed parameters, HOPE introduces a way for models to breathe and adapt long after the initial training is complete.

HOPE represents a definitive shift from structural depth to computational depth. It is an architecture that treats the forward pass not just as a static calculation, but as a mini-training session. This allows the model to modify its own internal logic and “study” the context as it processes every single token in real-time, effectively learning as it thinks.
Note on Context: This exploration into the HOPE architecture is a direct continuation of our previous analysis, Nested Learning: Is Deep Learning Architecture an Illusion?, where I discussed the theoretical shift from viewing architectures and optimizers as separate entities. If you haven’t read that yet, I highly recommend starting there to understand the philosophical “why” behind this architectural “how.”
- HOPE Core Innovation: Self-Modifying Weights
- The Continuum Memory System (CMS): Decoding the Multi-Level Brain
- Performance Benchmarks: The “10 Million Token” King
- The M3 Optimizer: The High-Performance Engine
- Conclusion
- References
HOPE Core Innovation: Self-Modifying Weights
To truly appreciate the HOPE architecture, we must first look at the “Achilles’ heel” of the modern Transformer. In a standard model like GPT-4, the “logic” of the model is frozen in place. When a Transformer processes a word, it uses static projection matrices – known as 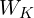 (Keys),
(Keys), 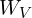 (Values), and
(Values), and 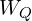 (Queries) – which were learned during months of pre-training and never change again.
(Queries) – which were learned during months of pre-training and never change again.
Imagine trying to navigate a brand-new city using a map that was printed ten years ago. You can see the streets, but you can’t see the new construction, the road closures, or the changing traffic patterns. This is the “Static Weight” problem. The Transformer sees every token through a fixed lens, limited by its past training.

The Leap to “Self-Referential” Titans
HOPE replaces these frozen, static “maps” with Self-Modifying Memories. Instead of a fixed matrix 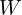 , HOPE uses a dynamic module (
, HOPE uses a dynamic module (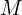 ) that acts like a living, breathing optimizer. This creates a “Self-Referential” system where the model doesn’t just process data – it studies it in real-time.
) that acts like a living, breathing optimizer. This creates a “Self-Referential” system where the model doesn’t just process data – it studies it in real-time.
- Generating Internal Targets: In a standard model, the “Value” of a word is just a fixed vector. In HOPE, the model uses its own current memory state to generate its own target values (
v^
- The Internal
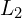 Objective: To refine its memory, the model performs a local mathematical operation known as Regression. It calculates the difference between its current “guess” and the actual data it is seeing. If there is a gap – meaning the model is “surprised” by a new context – it immediately triggers an update.
Objective: To refine its memory, the model performs a local mathematical operation known as Regression. It calculates the difference between its current “guess” and the actual data it is seeing. If there is a gap – meaning the model is “surprised” by a new context – it immediately triggers an update.
- Decoupled Gradient Descent (DGD): This is the engine of self-modification. While a normal model only uses “Gradient Descent” during its training phase, HOPE runs a specialized version called DGD during the forward pass (the moment it is talking to you). It uses a “Learning Rate” (
η) and a “Retention Gate” (α) to decide exactly how much of its old logic to discard and how much new information to “write” into its weights.
The “Neural Optimizer” vs. The “Matrix Lookup”
Crucially, the memories () in HOPE are not just simple tables of numbers. They are 2-Layer Residual MLPs (Multi-Layer Perceptrons).
This is a vital distinction. Most “memory-based” AI models just store a list of facts. Because HOPE’s memory is a non-linear neural network itself, it can store complex logic and patterns. If a standard Transformer is a library (a collection of static books), HOPE is a scholar living inside the library, constantly taking notes, updating their theories, and changing their mind as they read through the stacks.
The “Anchor” Query
To prevent this self-modifying system from drifting into mathematical chaos, HOPE keeps one small part of the process static: the Query projection (Wq). This acts as a stable “anchor” or a consistent “viewpoint.” While the model’s understanding of the world (the Keys and Values) is constantly evolving and rewriting itself, its way of asking questions (the Query) remains stable, ensuring the model stays grounded and coherent even across millions of tokens of text.
In short, HOPE doesn’t just have a “context window” that it looks through; it has a brain that adapts its own wiring to fit the context it is currently exploring.
The Continuum Memory System (CMS): Decoding the Multi-Level Brain
If the Self-Modifying Weights are the “active logic” of the HOPE architecture, the Continuum Memory System (CMS) is its profound “long-term storage.”
In the world of standard AI, memory is usually a binary choice. You either have Short-Term Memory (the context window), which is incredibly detailed but disappears the moment the conversation gets too long, or you have Long-Term Memory (the pre-trained weights), which are permanent but cannot be updated without a massive, expensive training run.
The CMS replaces this “all-or-nothing” approach with a spectrum of memory, creating a hierarchical architecture that mimics the varying frequencies of the human brain.
The “Heartbeat” of Artificial Intelligence
The core of the CMS is the concept of Update Frequency (f). Instead of a single, flat layer of processing, a HOPE block contains a chain of neural modules (MLPs), each operating at a different “heartbeat.”
- The High-Frequency Level (The “Sprint”): This level updates very often – perhaps every 512 tokens. It acts as the model’s “Working Memory,” capturing the fleeting nuances of the current paragraph, such as specific names, tones, or immediate instructions.
- The Mid-Frequency Level (The “Stride”): Updating every 2,048 tokens, this level filters out the noise of individual words to track larger themes. It maintains the continuity of a chapter or a long technical explanation.
- The Low-Frequency Level (The “Marathon”): This is the most persistent level, updating only every 8,192 tokens or more. It acts as the model’s “Deep Archive.” By the time information reaches this level, it has been compressed and refined, ensuring that the most vital “needles” of knowledge are stored safely for the long term.
A Synergy of Speed and Capacity
The brilliance of HOPE lies in the partnership between the Self-Modifying Titans (discussed in Section 1) and the CMS.
The Titans are fast and complex, but they have a small capacity—they are built for agility, not bulk storage. The CMS, on the other hand, provides the massive capacity needed for long-context reasoning. As information passes through the HOPE module, the “Fast” Titans adapt to the immediate data and then hand off the essential insights to the “Slow” CMS levels for persistent storage. This “hand-off” mechanism ensures that the model can handle a sequence of 10 million tokens without getting “overloaded” or confused.
Solving Catastrophic Forgetting: The Language Test
The most powerful proof of the CMS’s design is its ability to stop Catastrophic Forgetting. In traditional AI, if you try to teach a model two different tasks one after the other, the second task often “overwrites” the first.
The researchers tested this by having HOPE learn two rare languages (Manchu and Kalamang) in sequence.
- Standard ICL (Transformers): As the model learned the second language, its accuracy on the first plummeted. The context window simply couldn’t segregate the two distinct logic systems.
- HOPE with CMS: Because it has multiple “levels” of memory, HOPE was able to store the grammar rules of the first language in its lower-frequency (slower) levels while using its higher-frequency (faster) levels to absorb the second language.
By the end of the test, HOPE had effectively “recovered” its ability to translate both languages perfectly. It proved that by exploiting the extra axis of memory levels, we can build AI that doesn’t just store data, but organizes it across different timescales – just as the human brain separates a fleeting thought from a life-long skill.


Performance Benchmarks: The “10 Million Token” King
In the world of AI, benchmarks are the “stress tests” that separate theoretical promises from real-world performance. While many architectures claim to handle “long context,” they often crumble when the “haystack” of data becomes too large, or the “needle” of information becomes too subtle.
The HOPE architecture hasn’t just improved upon these benchmarks; it has essentially redefined the ceiling of what is computationally possible, moving the goalposts from the standard 128,000 tokens to a staggering 10 million tokens.
The “Needle-In-A-Haystack” (NIAH) Revolution – To understand why this is significant, imagine a “Needle-In-A-Haystack” test: you hide one specific sentence inside a massive book and ask the AI to find it.
- The Single Needle: Most modern models (like GPT-4 or Claude) can find a single fact reasonably well.
- The Multi-Key Challenge: The real difficulty arises in Multi-Key/Multi-Value tasks. This is like hiding ten different keys, each opening ten different locks, and asking the AI to describe the contents of the final box.
- The Result: Standard recurrent models like RWKV-7 and even previous state-of-the-art architectures like “Titans” see their accuracy collapse (dropping to near zero) as the document grows toward 1 million tokens. HOPE, however, maintains near-perfect accuracy even at the 10-million-token mark. By using its self-modifying weights to “compress” and “study” the data as it reads, HOPE ensures that no fact is lost to the noise of the haystack.
BABILong: Reasoning Across a Library – It is one thing to recall a fact; it is quite another to reason with it. The BABILong Benchmark evaluates whether a model can solve complex problems by connecting facts spread across millions of words.

In these tests, standard Transformers – even when augmented with RAG (Retrieval-Augmented Generation) – show a sharp “performance cliff.” Once the sequence length crosses 256K tokens, their logic begins to unravel. HOPE, by contrast, shows a “flat line” of success. Whether the document is 1,000 words or 10,000,000 words, HOPE’s ability to categorize and store information in its CMS levels enables it to perform high-level reasoning previously reserved for humans reading a multi-volume series of books.
The Logic Test: Beating the “Zero-Percent” Barrier – Perhaps the most shocking result from the HOPE research is found in Formal Language Recognition. These are mathematical tests that require a model to follow a strict logical state (e.g., “Is there an even number of ‘1’s in this 10,000-character string?”).
- The Transformer Failure: Because Transformers have a “fixed depth” (they can only look at the whole sequence at once with a limited number of layers), they are theoretically incapable of tracking these states over long distances. The standard Transformer scored 0.0%.
- The HOPE Triumph: Because HOPE uses Non-Linear Recurrence (that 2-layer MLP memory), it acts like a logical computer. It achieved a perfect 100% accuracy on these tasks. This proves that HOPE isn’t just a “memory bank” – it is a logical engine that can track states with mathematical precision.
Fuzzy Recall: The “Human” Touch – Finally, the research looked at Fuzzy In-Context Recall. Most AI models are great at finding an exact word match, but they struggle when the retrieval requires understanding a concept that is “almost” like the query.

On the MAD (Mechanistic Analysis and Design) benchmark, HOPE actually outperformed standard Transformers in Fuzzy Recall (52.1% vs 47.9%). This suggests that HOPE’s self-referential updates enable it to capture the essence and meaning of information rather than just its literal characters. It doesn’t just “remember” the text; it “understands” it deeply enough to retrieve it even when the prompt is slightly vague or different from the source.
The takeaway is clear: HOPE has conquered the context window. It is the first architecture that truly scales to the size of an entire library without losing its logical mind.
The M3 Optimizer: The High-Performance Engine
In the world of machine learning, an architecture is only as good as the optimizer that trains it. If the HOPE architecture is the “brain,” then the optimizer is the “engine” or the “fuel” that drives the learning process. For decades, the industry has relied on AdamW – a reliable but “flat” optimizer that treats all weight updates with the same general logic.
However, a multi-level, self-modifying system like HOPE requires something far more sophisticated. To meet this challenge, the researchers introduced a specialized engine: the M3 Optimizer (Multi-scale Momentum Muon).
Beyond “One-Size-Fits-All” Learning
To understand why M3 is revolutionary, we have to look at how a standard optimizer works. Traditional optimizers track “momentum” – essentially a memory of past gradients – to decide which direction to move the model’s weights. The problem? They usually only track one scale of momentum.
M3, as the name suggests, introduces Multi-scale Momentum.
- The Marathon Analogy: Imagine a professional runner. A basic optimizer only looks at the runner’s last step to predict the next one. M3, however, tracks three things simultaneously: the rhythm of the current stride (short-term), the pace of the current lap (mid-term), and the overall energy expenditure of the entire marathon (long-term).
- The Benefit: By tracking gradients across these different “scales” of time, M3 can navigate the complex mathematical landscapes of Nested Learning without getting stuck in “local minima” (mathematical dead-ends) that would trip up a simpler optimizer like AdamW.
The “Muon” Heritage: Precision and Orthogonality
The “M” in M3 also stands for Muon, referencing a high-performance optimization technique known for its mathematical “orthogonality.” In simple terms, this means M3 ensures that the updates it makes to the model’s weights don’t “interfere” with each other.
In a hierarchical model like HOPE, where you have different memory levels updating at different frequencies, “interference” is a major risk. If the fast-learning level and the slow-learning level try to move the weights in conflicting directions, the model becomes unstable. M3 uses its Muon-inspired logic to coordinate these updates, ensuring that every level of the “Ensemble” is working in harmony.
Proving the Power: The ImageNet and 1.3B Tests
The researchers didn’t just theorize about M3; they put it to the test against the best optimizers in the world, including AdamW and the original Muon.

- Vision Tasks (ImageNet-21K): When training Vision Transformers (ViT), M3 achieved significantly lower Test Loss and Train Loss than its competitors. In AI, this is known as “better generalization”—the model didn’t just memorize the data; it actually understood the underlying patterns better.
- Language Tasks (1.3B Scale): When scaled up to a 1.3-billion parameter language model, M3 outperformed the industry standards in common-sense reasoning and perplexity (prediction accuracy).
Efficiency: High Intelligence, Low Cost
One of the biggest fears in AI research is that more complex optimizers will be too “heavy” to run on standard hardware. The paper addresses this directly in Figure 12, comparing training times.
While M3 is slightly more complex than a “bare-bones” optimizer because it manages multiple “memories” (momenta), it was found to be on par with AdaMuon in terms of efficiency. For a negligible increase in training time (approx. 5-10%), M3 delivers a massive leap in how “smart” the resulting model becomes. It is a high-performance engine that doesn’t guzzle extra fuel.
The “Nested” Philosophy
In the end, M3 is the perfect realization of the Nested Learning (NL) paradigm. Under this view, the optimizer isn’t just a tool used to train the model – the optimizer itself is a form of associative memory. M3 “remembers” the history of the gradients so well that it becomes part of the model’s intelligence. It is the final piece of the puzzle that allows HOPE to transcend the limits of the static Transformer and become a truly dynamic, self-evolving system.
Conclusion
The HOPE architecture is more than just an incremental update to the Transformer; it is a fundamental rethinking of what “Depth” means in Silicon. For years, we thought the only way to make AI smarter was to make the “static brain” bigger. The researchers behind Nested Learning have shown us a different path: making the brain more active.
Why This Matters for the Future of AI:
- True Personalization: Imagine an AI that doesn’t just “remember” your name in a chat, but actually learns your personal coding style or writing voice in real-time and updates its internal logic to match yours.
- Infinite Contextual Reasoning: We are moving toward a world where you can feed an AI an entire library of medical textbooks or thousands of lines of legal code, and it won’t just “search” them – it will understand and optimize its weights to reason through them.
- The End of the “Context Window”: The arbitrary limits on how many tokens an AI can “see” are finally dissolving.
The authors honestly note that catastrophic forgetting isn’t “solved” – after all, a finite machine can’t store infinite information perfectly. However, by exploiting the extra axis of “levels” rather than just stacking more layers, HOPE provides a roadmap for AI that can learn, adapt, and remember with a sophistication that finally mirrors the human mind.






100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning