


VideoRAG, or Retrieval-Augmented Generation for Extreme Long-Context Videos, is a novel framework designed to enable large language models to comprehend multi-hour video content efficiently. Traditional large video-language models (LVLMs) struggle with long durations due to context limits and computational overhead, often losing semantic continuity across scenes or episodes.
To address this, VideoRAG combines graph-based textual knowledge grounding with multimodal context encoding to retrieve and synthesise key information, rather than processing every frame. This retrieval-driven design allows it to reason across long videos, maintain semantic accuracy, and deliver context-rich answers, making it a scalable solution for accurate long-form video understanding.
By the end of this article, we’ll understand:
- VideoRAG, and how it extends traditional RAG to multi-hour videos.
- It’s dual-channel architecture, which combines graph-based textual grounding with multimodal context encoding.
- Complete retrieval pipeline, from query reformulation to LLM-based filtering and final generation.
- Key results and ablation insights showing how graph reasoning and visual grounding boost comprehension.
1. Motivation: Why Text-Only RAG Fails for Videos?
While text RAG efficiently fetches paragraphs or knowledge snippets, video introduces new challenges:
| Challenge | Explanation |
|---|---|
| Multi-modality | Videos mix visual frames, audio, and text, each carrying unique semantics. |
| Temporal Continuity | Events evolve over minutes or hours, requiring memory beyond frame-level context. |
| Cross-Video Reasoning | Real-world concepts span multiple videos (e.g., multi-lecture courses). |
| Efficient Retrieval | Searching across terabytes of visual data must be lightweight and precise. |
Existing LVLMs, such as VideoLaMA3 and LLaVA-Video, perform well on short clips but collapse on multi-hour sequences due to these issues.
2. What Is VideoRAG?
VideoRAG is the first RAG framework explicitly designed for long-context video comprehension.
It unites graph-based textual knowledge grounding with multimodal context encoding, creating a hybrid index that enables any LLM to reason over visual, auditory, and textual signals without requiring retraining.

2.1 Core Innovations in VideoRAG
- Graph-based Textual Knowledge Grounding – builds a structured graph of entities and relationships extracted from video transcripts and captions.
- Traditional video analysis pipelines often treat transcripts or captions as linear text. VideoRAG goes a step further – it transforms this information into a structured knowledge graph. Each node in this graph represents an entity, while the edges define the relationships between them.
- By mapping knowledge in this way, VideoRAG captures semantic connections across scenes, clips, and even different videos.
- Multi-Modal Context Encoding – generates embeddings for both text chunks and visual clips for fast retrieval.
- Videos aren’t just words but a fusion of visual frames, spoken audio, and contextual cues. To represent this diversity, VideoRAG employs a multi-modal encoder that generates dense embeddings combining both textual and visual information. This ensures that important details like objects, settings, and speaker gestures are embedded alongside the dialogue or captions.
- By aligning visual and textual modalities in a shared vector space, the system can efficiently retrieve video segments based on meaning rather than keywords.
- LLM-based Retrieval Filtering and Generation – uses lightweight LLM modules for query reformulation, clip selection, and final synthesis.
- Unlike many LVLMs that require fine-tuning on massive datasets, VideoRAG is entirely training-free. It works as a plug-and-play retrieval layer, integrating with any existing LLM to provide contextually grounded video information.
- This design dramatically reduces computational cost and makes the system scalable, adaptable, and easy to deploy.
3. The VideoRAG Architecture
The architecture unfolds in three modules as follows –
3.1 Videos as Knowledge Base

Raw videos – lectures, documentaries, or entertainment – form the knowledge corpus. Each is segmented into short clips (≈ 30 seconds), enabling fine-grained analysis.
- Input: A collection of videos.
- These videos act as knowledge sources, analogous to text documents in a normal RAG.
- Each video is treated as a multi-modal corpus containing:
- Visual frames
- Audio speech
- On-screen text
- Descriptive captions
- The pipeline will extract both textual knowledge (via captions / ASR) and visual knowledge (via frame encoders).
Goal: transform these raw videos into a structured and searchable knowledge base.
3.2 Multi-Modal Video Knowledge Indexing

Graph-based Textual Knowledge Grounding
- Visual stream processed via a Vision-Language Model (VLM) to create descriptive captions.
- Audio stream transcribed by ASR (Automatic Speech Recognition).
- The captions
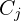 and transcripts
and transcripts 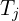 form pairs (, ) for each clip, which are later transformed into nodes and relations via LLM-based entity extraction.
form pairs (, ) for each clip, which are later transformed into nodes and relations via LLM-based entity extraction. - An entity-relation mapper parses these chunks to build a sub-knowledge graph
(𝒩ₕ, ℰₕ)per video -> nodes = entities, edges = relations. - Result: a semantic sub-graph representing entities and their relations.
Hybrid Index Construction
After per-video graphs are built, they are merged into a global knowledge graph 𝒢.
- Text chunks embedded by a text encoder TEnc(⋅).
- Video clips embedded by a multi-modal encoder MEnc(⋅), such as CLIP or ImageBind.
- Sub-graphs from all videos are unified into a global knowledge graph 𝒢 and stored with their embeddings:
Together, these form the Hybrid Index = {Graph + Text + Visual Embeddings}, which supports both semantic and visual retrieval.
3.3 Multi-Modal Retrieval Paradigm

This shows what happens at inference / question-answering time. Let’s understand this phase with an example –
When a user submits a query (e.g., “What are OpenAI o1 and o1 Pro Mode in ChatGPT?”), VideoRAG performs:
- Query Reformulation – LLM rewrites the question in a declarative manner (similar to “retrieval requests” in prior RAG systems).
- Encoders applied:
- TEnc(·) → to get the query’s text embedding.
- MEnc(·) → to extract visual cues implied by the question (e.g., objects, scenes).
- Graph-based Clip Retrieval: Uses the knowledge graph to find semantically related clips (via entity and relation links).
- Embed-based Retrieval: Simultaneously performs:
- Video-clip retrieval using Eᵥ,
- Text-chunk retrieval using Eₜ.
- LLM-based Filtering (“Judge”): A lightweight LLM module evaluates retrieved results to filter irrelevant content – ensuring only top-relevant clips/chunks are kept. This adds an intelligent post-retrieval gating step.
- Answer Generation: The final answer stage fuses:
- Retrieved video knowledge Vᵛ
- Retrieved text knowledge ℋ
- The user’s original query
and sends everything to a VLM (Vision-Language Model) for reasoning and response generation.
The output is a textual answer grounded in both the knowledge graph and retrieved clips.
Overall Workflow (Condensed)
| Stage | Process | Key Output |
|---|---|---|
| (a) | Raw Videos → Clips + Modalities | Video Corpus |
| (b1) | Caption + ASR → Entities + Relations | Sub-Graphs |
| (b2) | Encode Text + Visual → Hybrid Index | 𝒢 (Global Graph) + Embeddings |
| (c1) | Query Reformulation + Embedding Search | Candidate Chunks / Clips |
| (c2) | LLM Filtering + Fusion | Final Answer |


4. VideoRAG Framework System Design
We will focus on two main challenges –
- Multi-Modal Video Knowledge Indexing – organises visual, audio, and semantic information from videos into a retrievable knowledge base.
- Knowledge-Grounded Information Retrieval – retrieve the most relevant segments to answer a query and feed them to an LLM for final generation.
4.1 System Design for Multi-Modal Video Knowledge Indexing
This section elaborates on the first half of the indexing pipeline (the other half being Multi-Modal Context Encoding, described later). Its goal is to convert multi-modal video content into structured, semantically rich textual knowledge that can be efficiently indexed and retrieved.
VideoRAG introduces two sub-modules for indexing:
- Graph-based Textual Knowledge Grounding – transforms multi-modal signals (vision + audio) into structured text representations while preserving semantic and temporal coherence.
- Multi-Modal Context Encoding – handles fine-grained visual–text interactions (covered later).
Together, these features enable VideoRAG to index long-context videos without compromising multimodal richness.
Let’s dive into Graph-based Textual Knowledge Grounding first.
Graph-based Textual Knowledge Grounding

Dual-Stream Processing: Vision + Audio
- Vision-Text Grounding
- Each video V is divided into m short clips S1,…, Sm.
- For each clip Sj, we:
- Uniformly sample l frames (F1,…, Fk) to capture temporal diversity.
- Use a Vision-Language Model (VLM) to generate a caption Cⱼ that summarises visual + scene dynamics.
Mathematically:

where,
Tj = transcript for clip Sⱼ,
Fk = sampled frames (k ≤ 10 for efficiency).
Hence, the VLM takes both visual frames and text transcripts as input prompts to produce context-aware captions describing objects, actions, and scene changes.
- Audio-Text Grounding
- To capture spoken dialogue and narration, they run Automatic Speech Recognition (ASR) on each clip:
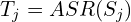
where is the transcribed text.
- To capture spoken dialogue and narration, they run Automatic Speech Recognition (ASR) on each clip:
- Unified Textual Representation
- For a video V with m clips, the set of all caption-transcript pairs is:
![V^t = { (C_l, T_l) \mid l \in [1, m] }](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-3824d4ae3c05138860a98c05ecf0ea97_l3.png)
This becomes the textual knowledge representation for that video.
- For a video V with m clips, the set of all caption-transcript pairs is:
Semantic Entity Recognition & Relationship Mapping

After generating textual knowledge, VideoRAG must organise it into a graph for structured retrieval.
- Text Segmentation
- Long video descriptions Vᵗ are split into manageable chunks ℋₗ ⊂ Vᵗ using pre-defined length windows.
- Each chunk preserves semantic continuity and temporal order.
- Purpose: make sub-graphs that can be processed by LLMs without context overflow.
- Entity-Relation Extraction
- Each chunk ℋₗ is passed through an LLM to identify entities (nodes 𝒩ₕ) and relations (edges ℰₕ).
- This creates a local sub-graph gₕ = (𝒩ₕ, ℰₕ).
- Example from the text:
- For the phrase – “GPT-4 utilises transformer architecture for advanced natural language understanding.”, the LLM extracts entities “GPT-4” and “transformer architecture”, and creates the edge (“GPT-4” → “uses transformer architecture”).
- This step builds a semantic knowledge graph from video content, capturing how concepts relate within and across videos.
Each video is thus represented as a set of nodes (entities) and edges (relationships) as gₕ = (𝒩ₕ, ℰₕ). Later in the pipeline, these sub-graphs are merged into a global multi-video knowledge graph 𝒢 for cross-video reasoning.
Incremental Graph Construction & Cross-Video Knowledge Integration
After building per-video sub-graphs (𝒩ₕ, ℰₕ) in the previous section, this part describes how VideoRAG fuses them into a unified, evolving global knowledge graph 𝒢.
- Entity Unification and Merging – Entities that are semantically equivalent across videos are merged into a single node. Example: “GPT-4”, “OpenAI GPT-4”, and “GPT4-model” → unified node “GPT-4”.
- Dynamic Knowledge Graph Evolution – As new videos are added, the graph expands by:
- Integrating new entities and relations discovered in unseen videos.
- Establishing new semantic links between existing nodes (e.g., new AI architectures or relationships).
This bi-directional growth lets VideoRAG both reinforce existing structures and accommodate emerging concepts – maintaining adaptability as the corpus scales.
- LLM-Powered Semantic Synthesis
- To keep semantic consistency, LLMs generate unified entity descriptions by synthesising information from all videos where an entity appears.
- This ensures each entity’s representation is comprehensive, context-consistent, and semantically accurate across the knowledge base.
- Example: if “Transformer” appears in multiple contexts (vision and language), the LLM merges its definitions into one cohesive node description.
Formal Definition of the Unified Knowledge Graph

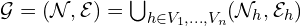
Here:
- 𝒩: set of all entities across videos.
- ℰ: set of all relations (semantic edges).
- 𝒩ₕ, ℰₕ: entity-relation pairs extracted from each video chunk ℋh.
Thus, as all videos V1,…, Vn are processed, their sub-graphs merge into one comprehensive graph 𝒢.
Text Chunk Embedding

To make these graphs searchable, VideoRAG encodes textual chunks into dense vectors.
- For each text chunk
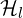 :
: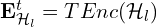
where TEnc(⋅) is a text encoder (e.g., BERT, MiniLM). - All embeddings from the full set H form
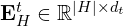 , with ∣H∣ = number of chunks, and
, with ∣H∣ = number of chunks, and 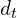 = text embedding dimension.
= text embedding dimension.
These 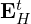 vectors enable fast semantic retrieval of textual content within the graph.
vectors enable fast semantic retrieval of textual content within the graph.
Multi-Modal Context Encoding

Even after textual grounding, visual nuances (lighting, colour, spatial layout, fine object details) need to be preserved. Hence, a dedicated multi-modal encoder handles this.
- Each video clip S is transformed into a multi-modal embedding:
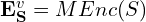
where:- MEnc(⋅) = multi-modal encoder (built upon frameworks like CLIP and ImageBind).
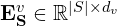 – visual embeddings dimension
– visual embeddings dimension 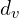 .
.
This encoder maps both visual content and query text into a shared embedding space, enabling cross-modal semantic retrieval.
4.2 System Design for Knowledge-Grounded Information Retrieval
This stage operates on the previously built hybrid index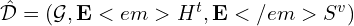
to retrieve relevant content (both text and video clips) for a user query q. The process integrates textual semantic matching, visual retrieval, and LLM-based filtering.
Textual Semantic Matching
This branch searches the graph-based textual knowledge. The four sequential steps form the retrieval pipeline:

- Query Reformulation – The user query is first rewritten by an LLM into a declarative, structured query to facilitate easier retrieval. This reformulated text is then used for entity matching.
- Entity Matching –
- The system calculates semantic similarity between entities in the query and those in the knowledge graph 𝒢.
- Matched entities anchor retrieval to their associated text chunks ℋ.
- Chunk Selection – Using a GraphRAG-style method, VideoRAG selects the most relevant text chunks ℋₗ that best explain or support the query.
- Video Clip Retrieval
- Each selected chunk ℋ corresponds to multiple video clips.
- Those clips are retrieved and combined into the final textual-retrieval set
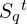 .
.
Visual Retrieval via Content Embeddings
This branch complements textual retrieval with direct visual evidence.

- Each video clip S has a multi-modal embedding
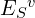 .
. - The query is also embedded using the same encoder MEnc(⋅).
The retrieval works in two sub-steps:
- Scene Information Extraction from Query
- An LLM expands the query into a scene-centric description, e.g.
- “In the movie, what colour is the car that chases the main character through the city?” → “A car chasing someone through city streets with buildings and traffic in the background.”
- This reformulation guides scene-based alignment.
- Cross-Modal Feature Alignment
- Both query and video embeddings are projected into the same latent space:
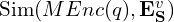
- The top-K most similar clips form the visual retrieval set
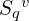 .
.
- Both query and video embeddings are projected into the same latent space:
LLM-Based Video Clip Filtering
To remove irrelevant clips and retain only those that truly answer the question, VideoRAG utilises a lightweight LLM Judge module.
Formally:


- The LLM Judge returns 1 if a clip is relevant based on both textual and visual content.
- Prompts are carefully designed so the LLM evaluates factual relevance and dismisses noise.
4.3 System Design for Query-Aware Content Integration and Response Generation
Once the relevant clips 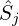 are ready, VideoRAG performs a two-stage content extraction followed by generation.
are ready, VideoRAG performs a two-stage content extraction followed by generation.
Visual Caption Enrichment
- For each filtered clip :
- Retrieve its ASR transcript
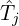 .
. - Sample k frames
 .
. - Feed both into a VLM to generate a refined visual caption
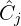 :
: 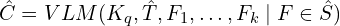
where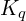 = query keywords.
= query keywords. - The pair
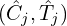 forms the enriched semantic representation.
forms the enriched semantic representation.
- Retrieve its ASR transcript
Fusion and Answer Generation
- Combine all retrieved clips
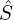 , enriched captions
, enriched captions 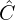 , and transcripts
, and transcripts 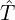 into a unified context
into a unified context 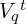 .
. - Merge this with the query q and send to a powerful LLM (e.g., GPT-4 or DeepSeek) for final reasoning and response generation.
The final reasoning step is expressed as: 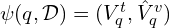
where textual and visual contexts are jointly used to synthesise the final answer.
Conceptual Flow of the Retrieval-to-Generation Phase
| Stage | Input | Operation | Output |
|---|---|---|---|
| 1. Query Reformulation + Entity Matching | User question | Graph-based RAG | Relevant text chunks ( ) ) |
| 2. Visual Retrieval | Reformulated scene query | Embedding similarity | Visual clip set |
| 3. LLM Judge Filtering |  | Relevance evaluation | Final clip set 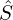 |
| 4. VLM Caption Enrichment | + ASR + Frames | Detailed visual captions | (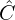 , , 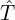 ) ) |
| 5. LLM Generation | Query + Context | Answer synthesis | Final textual response |
5. VideoRAG-Vimo Implementation
Follow the steps given below to implement the VideoRAG pipeline –
- Generate an OpenAI API key, which we will need to use gpt-4o-mini for the LLM-as-a-judge service.

- We will also utilise the Alibaba Dashscope service, with the Singapore or Beijing servers using qwen-vl-max-latest as the captioning model. Therefore, we need an API key for the Alibaba Model Studio, too. The free trial version (account and payment information mandatory) is usable till 1 million input and 1 million output tokens.

- Clone the official implementation repository of VideoRAG. The implementation is in the form of a desktop application named ‘VIMO’.
git clone https://github.com/HKUDS/VideoRAG.git
- Open the ‘Vimo-desktop’ folder, which contains all the required scripts.
cd Vimo-desktop
- Create a new conda environment, and install the necessary dependencies and models to be used in executing the whole VideoRAG pipeline via the VIMO desktop application.
conda create --name vimo python=3.11
conda activate vimo
# Core numerical and deep learning libraries
pip install numpy==1.26.4 torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2
# Video processing utilities
pip install moviepy==1.0.3
pip install git+https://github.com/Re-bin/pytorchvideo.git@58f50da4e4b7bf0b17b1211dc6b283ba42e522df
pip install --no-deps git+https://github.com/facebookresearch/ImageBind.git@3fcf5c9039de97f6ff5528ee4a9dce903c5979b3
# Multi-modal and vision libraries
pip install timm ftfy regex einops fvcore eva-decord==0.6.1 iopath matplotlib types-regex cartopy
# Audio processing and vector databases
pip install neo4j hnswlib xxhash nano-vectordb
# Language models and utilities
pip install tiktoken openai tenacity dashscope
# Server
pip install flask psutil flask_cors setproctitle
- Once the environment is set up, start the VideoRAG-Vimo backend server.
cd python_backend
python videorag_api.py
- We’ll see the following on the terminal once the backend server starts.

- After starting the backend service, we need to launch the frontend application, assuming “pnpm” is already installed on the system.
# Install dependencies
pnpm install
# Start development server
pnpm dev
- We are going to have the following on our terminal once the frontend application starts.

- After all these steps, our application successfully starts running.

- After providing the API keys, the Imagebind model, which is approximately 4.5GB in size, needs to be downloaded. The application itself initiates this process, and with a single click, it can be downloaded.
- Now we are good to go. Upload the set of videos, click “Start Analysing”, and once the videos have been analysed, pose the questions and receive the answers or responses in seconds.
6. VideoRAG Benchmark Evaluation and Results
The LongerVideos Benchmark
To evaluate performance, the authors created LongerVideos, the first large-scale benchmark for multi-hour, multi-video reasoning.
| Category | #Videos | #Queries | Duration | Description |
|---|---|---|---|---|
| Lecture | 135 | 376 | ~64 hrs | AI tutorials, RAG, and agent systems |
| Documentary | 12 | 114 | ~29 hrs | Wildlife, exploration, narration |
| Entertainment | 17 | 112 | ~42 hrs | Cultural, travel, and award content |
| Total | 164 | 602 | 134.6 hours | Diverse long-form comprehension corpus |
All data comes from open-access YouTube sources, ensuring reproducibility.
Evaluation Methodology for VideoRAG
Two complementary evaluation protocols were used:
| Protocol | Description |
|---|---|
| Win-Rate Comparison | Pairwise LLM-judged preference between VideoRAG and baselines (GPT-4o-mini as judge). |
| Quantitative Scoring | Likert-scale (1-5) evaluations for Comprehensiveness, Empowerment, Trustworthiness, Depth, and Density. |
Each experiment involved randomised answer positioning to avoid bias and multiple judgments per query for statistical reliability.
Results and Discussion
Overall Comparison
Across all metrics and categories, VideoRAG leads with an average 57.1 % win-rate, surpassing both NaiveRAG (42 %) and GraphRAG (43 %).
| Metric | Definition | Why VideoRAG Wins |
|---|---|---|
| Comprehensiveness | Coverage of all question aspects | Multi-modal fusion expands contextual scope |
| Empowerment | How answers aid understanding | Graph reasoning enables explainability |
| Trustworthiness | Factual accuracy and alignment | Grounded in ASR + VLM-generated content |
| Depth | Level of analytical detail | Rich cross-modal synthesis |
| Density | Information-to-redundancy ratio | Compact, relevant responses |
Ablation Study
To test robustness, two ablations were performed:
| Variant | Removed Module | Outcome |
|---|---|---|
| –Graph | Graph-based retrieval | Severe drop in semantic coherence |
| –Vision | Multi-modal encoder | Lost visual grounding and fine-grained details |
Both modules are indispensable, demonstrating the synergistic importance of structural and visual reasoning.
Comparative Baselines
| Model | Type | Limitation |
|---|---|---|
| NaiveRAG | Text-only chunk-based retrieval | No multi-modal reasoning |
| GraphRAG | Text-graph reasoning | Ignores visual content |
| VideoAgent | Visual-only multi-modal agent | Fails on long durations |
| NotebookLM | Transcript-based LLM assistant | Text-only, lacks grounding |
| VideoRAG (Ours) | Graph + Multi-Modal Retrieval | Efficient, scalable, and context-aware |
7. Conclusion
VideoRAG stands as a turning point in video-language research. It introduces a training-free, dual-channel retrieval system that merges the interpretability of graphs with the contextual richness of vision embeddings.
Key Takeaways:
- Processes unlimited-length
videosefficiently. - Builds interpretable knowledge graphs across multi-video corpora.
- Retrieves and synthesises textual + visual + audio signals coherently.
- Achieves state-of-the-art results on the LongerVideos benchmark.
- Outperforms both RAG and LVLM alternatives.





100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning